

| Last Updated | Changes |
| 9/14/2023 | First version published |
| 9/27/2023 | Updated to Automatic1111 Extension |
| 10/3/2023 | ComfyUI Simplified Example Flows added |
| 10/9/2023 | Updated Motion Modules |
| 11/3/2023 | New Info! Comfy Install Guide |
| 1/19/2023 | Basic ComfyUI Workflows Updated |
What is AnimateDiff?
AnimateDiff, based on this research paper by Yuwei Guo, Ceyuan Yang, Anyi Rao, Yaohui Wang, Yu Qiao, Dahua Lin, and Bo Dai, is a way to add limited motion to Stable Diffusion generations.
Supporting both txt2img & img2img, the outputs aren’t always perfect, but they can be quite eye-catching, and the fidelity and smoothness of the outputs has improved considerably since AnimateDiff first appeared!
There’s also a video2video implementation which works in conjunction with ControlNet, examples below!




Examples of video2video produced with ComfyUI (from our Civitai Socials!);
How can I run AnimateDiff?
There are currently a few ways to start creating with AnimateDiff – requiring various amounts of effort to get working. I’ve listed a few of the methods below, and documented the steps to get AnimateDiff working in Automatic1111 – one of the easier ways.
Requirements & Caveats
- Running locally takes at least 12GB of VRAM to make a 512×512 16 frame image – and I’ve seen usage as high as 21GB when trying to output 512×768 and 24 frames. If you have an RTX 3090+ you should be good for local generation.
- The latest VRAM estimates for Ubuntu are as follows (default settings 512×512, 16 frames, Torch 2.0, RTX 4090;
| Optimization Type | VRAM Usage |
|---|---|
| No optimization | 12.13 GB |
| Xformers/SDP | 5.6 GB |
| Sub-quadratic | 10.39 GB |
- Try to keep prompts below 75 tokens when generating locally! Prompts over 75 tokens will either exhibit no motion, or will be split into two different “scenes” – the second half of the frames being completely different from the first half. Note that negative prompts should be kept short also!
If you’re still having trouble with split scenes while using Automatic1111, check that the following settings in Automatic1111’s Optimization settings are enabled;
Pad prompt/negative prompt to be the same length
Persistent cond cache
Batch cond/uncond
- There’s no SDXL support right now – the motion modules are injected into the SD1.5 UNet, and won’t work for variations such as SD2.x and SDXL.
- We must download Motion Modules for AnimateDiff to work – models which inject the magic into our static image generations. The table below contains the Motion models currently available on Civitai.
| Model Name | Author | Link |
|---|---|---|
| V1.5 v2 (best of the official models) | AnimateDiff team | Civitai Model Version |
| V1.5 | AnimateDiff team | Civitai Model Version |
| V1.4 | AnimateDiff team | Civitai Model Version |
| TemporalDiff v1.0 | Ciara Rowles | Civitai Model Version |
| mm-Stabilized_high | Manshoety | Civitai Model Version |
| mm-Stabilized_mid | Manshoety | Civitai Model Version |
| improvedHumansMotion_refinedHumanMovement | Manshoety | Civitai Model Version |
| improved3DMotion_improved3DV1 | Manshoety | Civitai Model Version |
The following table contains Motion LoRA – LoRA, called in the prompt like a normal LoRA, which inject camera movement into the scene (examples below).
The following LoRA will only work with the V1.5 v2 Motion Module, above.
| MotionLoRA Model Name | Author | Link |
|---|---|---|
| v2_lora_ZoomOut | AnimateDiff team | Civitai Model Version |
| v2_lora_ZoomIn | AnimateDiff team | Civitai Model Version |
| v2_lora_RollingClockwise | AnimateDiff team | Civitai Model Version |
| v2_lora_RollingAntiClockwise | AnimateDiff team | Civitai Model Version |
| v2_lora_PanUp | AnimateDiff team | Civitai Model Version |
| v2_lora_PanDown | AnimateDiff team | Civitai Model Version |
| v2_lora_PanLeft | AnimateDiff team | Civitai Model Version |
| v2_lora_PanRight | AnimateDiff team | Civitai Model Version |
HuggingFace Space
If you’d like to test AnimateDiff on some pre-defined models, it can be accessed via this HuggingFace space. Note that it’s slow, there’s a queue, but it can output 512×768 images.

Google Colab
There are three AnimateDiff workbooks authored by @camenduru;
They are meant to be runnable on the Free Colab tier – but I hit 13.6GB VRAM usage while running, so keep an eye on that virtual GPU!

Note that both the Command Line and Gradio Colab interfaces are limited to 24 frames at 512×512 to try to keep below the Free-tier threshold.
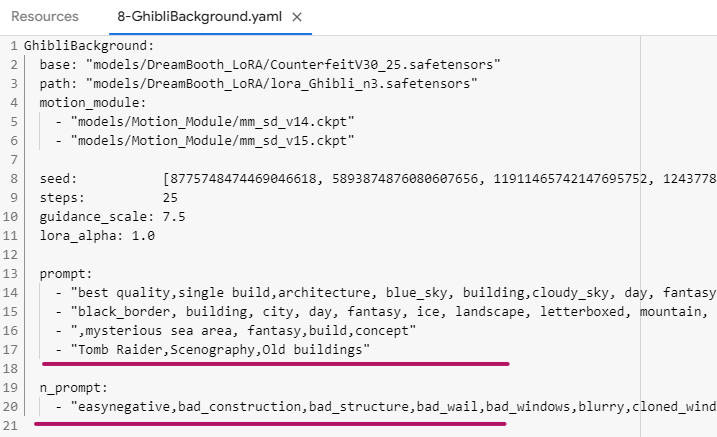
When using the headless Colab, you can edit the prompts by editing these (or creating your own) .yaml files. Outputs will appear in the animatediff/samples/modelname/sample directory.

Locally with Automatic 1111
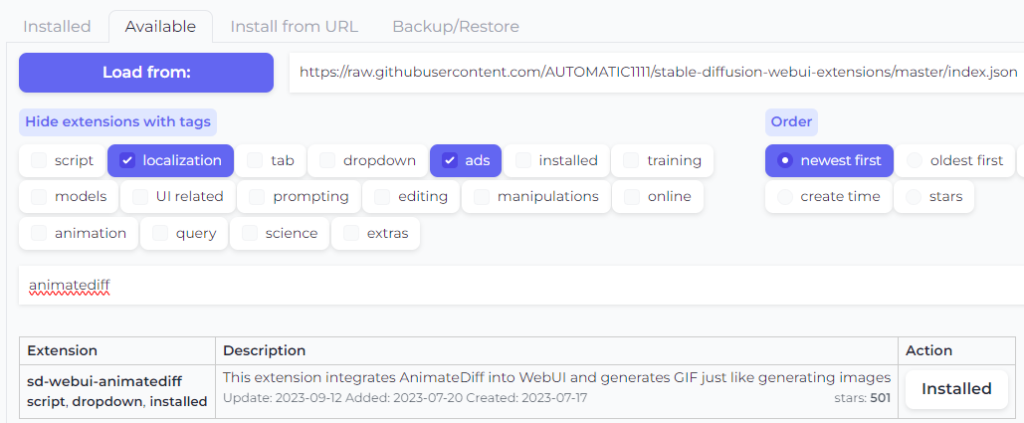
The best implementation of AnimateDiff for WebUI is currently Continue-Revolution’s sd-webui-animatediff.
Installing is as simple as heading to the Extensions > Available tab, clicking “Load From“, then searching for “animatediff“.
You’ll then need to download one of the available Motion Modules to be able to inject motion into your generations. Head to Civitai and filter the models page to “Motion” – or download from the direct links in the table above.
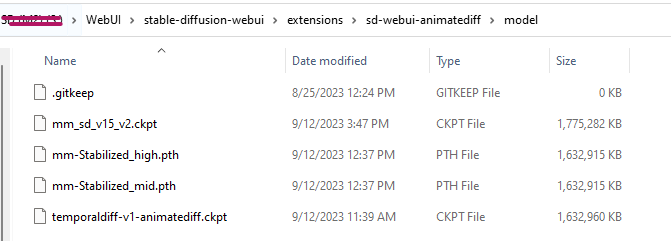
WebUI\stable-diffusion-webui\extensions\sd-webui-animatediff\model directoryIt’s now as simple as opening the AnimateDiff drawer from the left accordion menu in WebUI, selecting a Motion module, enabling the extension, and generating as normal (at 512×512, or 512×768, no hires. fix)!
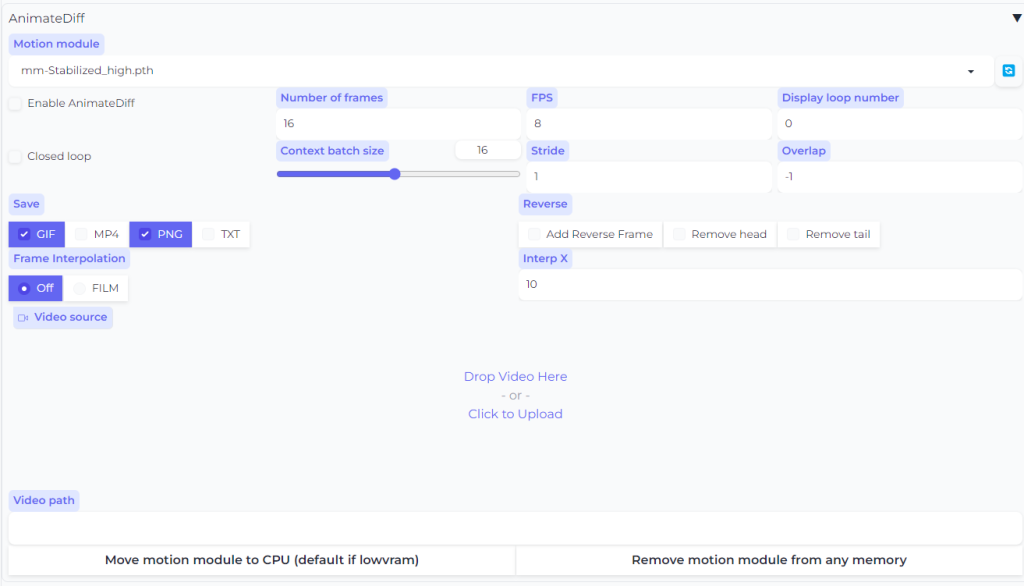
Auto1111 Advanced Usage
A number of additional settings were recently added to the Auto1111 Extension, allowing for mp4 output, video2video with ControlNet integration, and controllable camera positioning, with specially trained Motion LoRA!
- Motion LoRA – Available in the table above, from Civitai, Motion LoRA are saved in the standard LoRA folder, and are called in the prompt exactly like any other LoRA, to add subtle camera movements to the scene. There are eight camera movements to try.


- ControlNet support for Video to Video generation. If you include a Video Source, or a Video Path (to a directory containing frames) you must enable at least one ControlNet (e.g. Canny or Depth). There’s no need to include a video/image input in the ControlNet pane; Video Source (or Path) will be the source images for all enabled ControlNet units.
Auto1111 Bugs, Issues, & tips
There are a couple of problems with the current implementation of AnimateDiff in Automatic1111 WebUI that I’ve come across,
VAE doesn’t seem to be applied, and the more frames generated, the darker and more washed out our colors are.This doesn’t seem to affect the example images on the main AnimateDiff repo – Appears to be fixed! Enjoy beautiful colorful outputs!

- Many generations seem to have trouble unloading the Motion modules, leaving generation “stuck” at ~98% completion and GPU at 100% load. The only fix I’ve found is to close and re-start WebUI.

- You can generate with any SD 1.5 model, but some will turn out more muted and show less movement than others. I’ve had good results with the BeautyFool, Aniverse & HelloYoung25d models.
ComfyUI
For a full, comprehensive guide on installing ComfyUI and getting started with AnimateDiff in Comfy, we recommend Creator Inner_Reflections_AI’s Community Guide – ComfyUI AnimateDiff Guide/Workflows Including Prompt Scheduling which includes some great ComfyUI workflows for every type of AnimateDiff process.

ComfyUI Custom Nodes
Custom Nodes for ComfyUI are available! Clone these repositories into the ComfyUI custom_nodes folder, and download the Motion Modules, placing them into the respective extension model directory. Note that these custom nodes cannot be installed together – it’s one or the other.
Two of the most popular repos are;
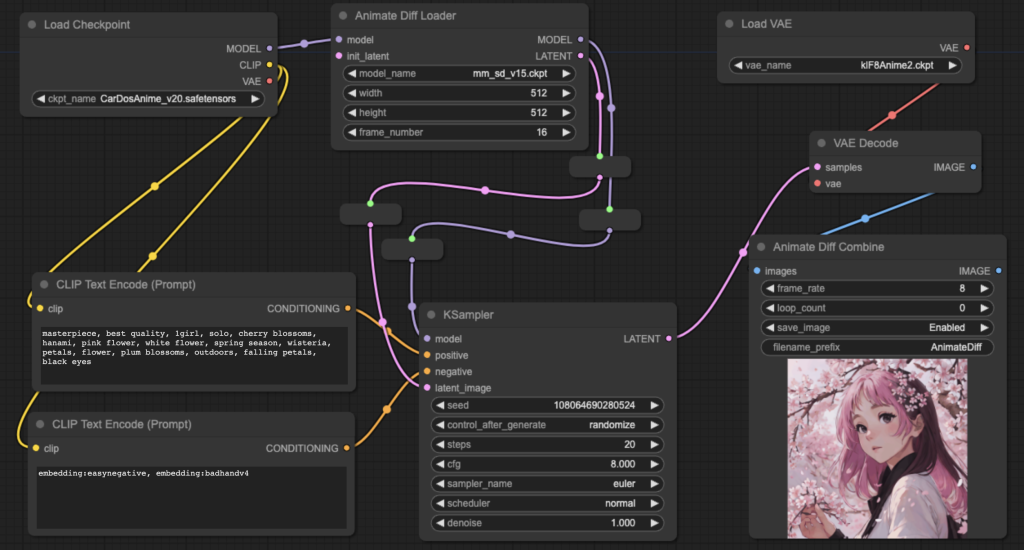
- Kosinkadink‘s comfyui-animatediff-evolved implementation. Adds some extra features to ArtVentureX’s implementation.
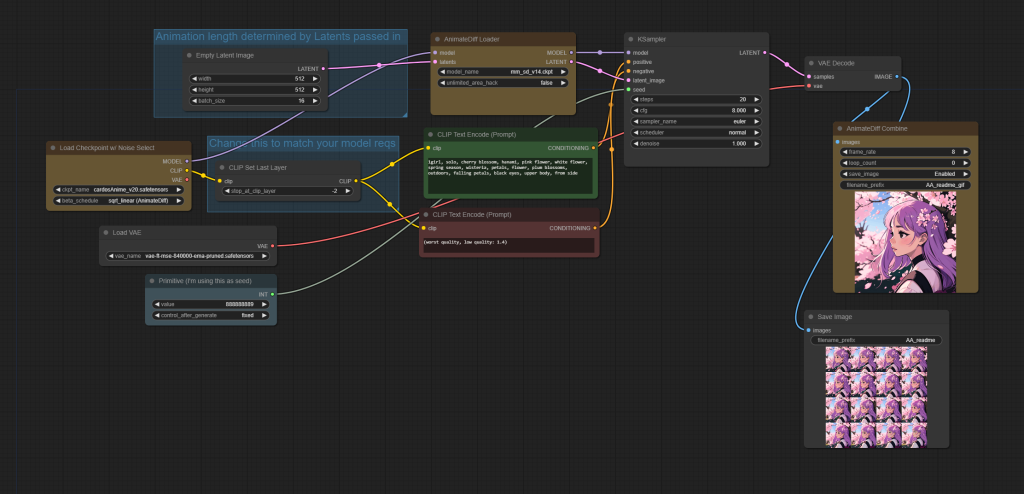


ComfyUI Example Workflows
The following workflows are laid out in a particularly easy to follow way, to help understand and control the workflow and outputs.
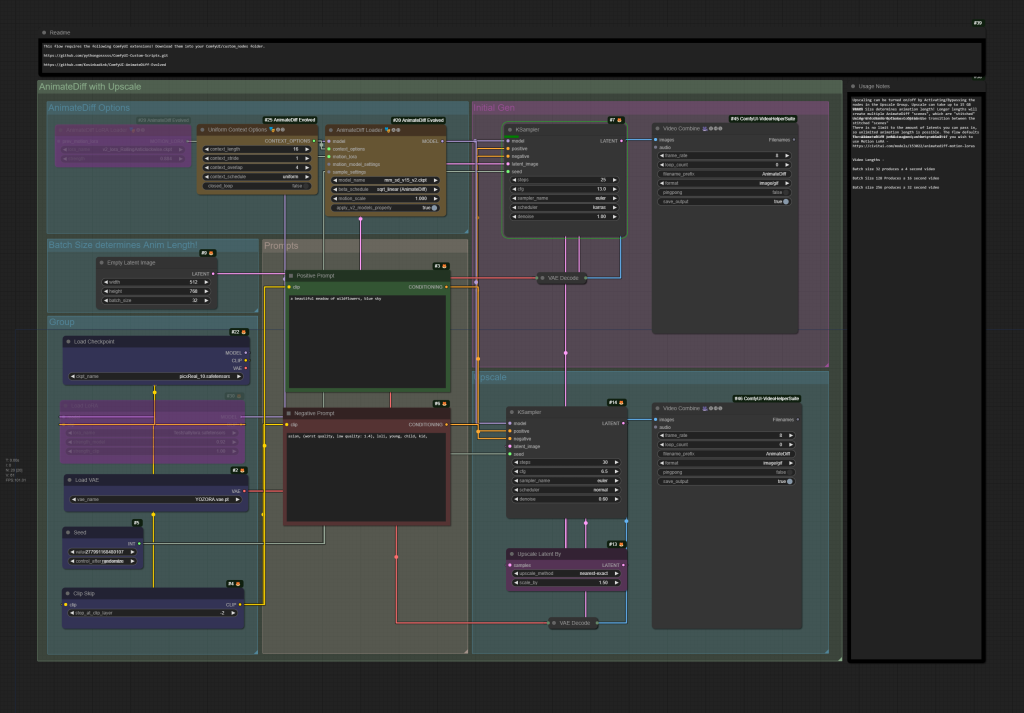
AnimateDiff with Motion LoRA, SD LoRA, and Upscaling
Simple AnimateDiff txt2video workflow, requiring the following custom nodes;
https://github.com/pythongosssss/ComfyUI-Custom-Scripts.git
https://github.com/Kosinkadink/ComfyUI-AnimateDiff-Evolved
Note that upscaling is VRAM intensive.
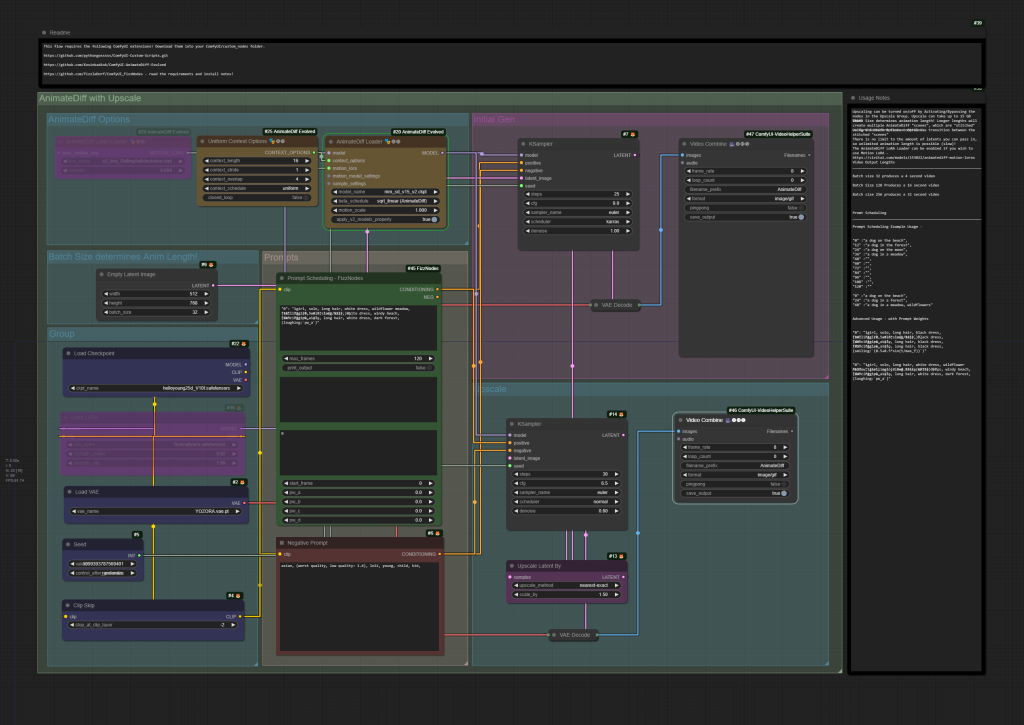
AnimateDiff with Motion LoRA, SD LoRA, Upscaling, and Prompt Scheduling
Prompt Scheduling workflow, requiring the following cutsom nodes;
https://github.com/pythongosssss/ComfyUI-Custom-Scripts.git
https://github.com/Kosinkadink/ComfyUI-AnimateDiff-Evolved
https://github.com/FizzleDorf/ComfyUI_FizzNodes
Note that upscaling is VRAM intensive.
The Future
We’re super excited to see where this tech is going, and will continue to update this guide frequently as new information and Motion modules become available!
