

| Last Updated | Changes |
| 8/12/2024 | First Version |
| 8/15/2024 | On-Site and Local LoRA Training Information |
| 9/10/2024 | Huge Update! All the latest Flux Info! |
| 9/12/2024 | Rapid Flux Training! |
| 11/21/2024 | Flux Tools released! |
| 22/27/2024 | Inpainting and Outpainting Update! |
| 7/30/2025 | Flux Kontext Pro and Max on Civitai |
| 7/31/2025 | Flux Krea Dev – New Model! |
What is Flux? Who made it?
In early August 2024, a team of ex-Stability AI developers announced the formation of Black Forest Labs, with the mission to; “develop and advance state-of-the-art generative deep learning models for media such as images and videos, and to push the boundaries of creativity, efficiency and diversity.”
Our Quickstart Guide to Flux.1 will help you understand what the model is, and how to start using it!
Shortly following the announcement, their first text-to-image diffusion model was released; Flux.1. Trained with 12 billion parameters, and based upon a novel transformer architecture, Flux has wowed the community with its fantastically good image fidelity and controllability!
Flux.1 consists of a number of distinct model variations;
- Flux.1 Krea [Dev] – developed in collaboration with Krea AI. FLUX.1 Krea [dev] is a new (July 2025) state-of-the-art open-weights model (can be used offline, locally) for text-to-image generation that overcomes the oversaturated ‘AI look’ to achieve new levels of photorealism with its distinctive aesthetic approach.

- Flux.1 [Pro 1.1 Ultra & Ultra Raw] – Pro 1.1 Ultra, and Ultra Raw are only available for use via API. You can use Black Forest Labs’ own API, or a number of their commercial partners, to generate images with Flux.1 Pro 1.1 Ultra, and Ultra Raw. The weights can’t be downloaded, and even if they could, the system requirements would be too high for use with consumer hardware.
Flux Pro 1.1 Ultra adds 4 megapixel, ultra high resolution outputs, while Ultra Raw captures a more natural, candid, aesthetic.


- Flux.1 [Pro 1.1] – Pro 1.1 is only available for use via API. You can use Black Forest Labs’ own API, or a number of their commercial partners, to generate images with Flux.1 Pro 1.1. Pro 1.1 supersedes Pro in many ways – it’s cheaper, and provides better quality images! The weights can’t be downloaded. Flux.1 [Pro] is available for use via the Civitai on-site Generator, as Model Mode: Pro 1.1.

- Flux.1 [Pro] – Pro is only available for use via API. You can use Black Forest Labs’ own API, or a number of their commercial partners, to generate images with Flux.1 Pro. Pro has largely been replaced by Pro 1.1, which is cheaper, more performant, and provides better outputs. The weights can’t be downloaded. Flux.1 [Pro] is available for use via the Civitai on-site Generator, as Model Mode: Pro.

- Flux.1 [Dev] – Dev is an open-weight, distilled, model for non-commercial applications. Distilled from Flux.1 [Pro], it provides similar quality and prompt-adherence capabilities while being more efficient; we can run it locally on consumer hardware. Flux.1 [Dev] is released under the Flux.1 Dev Non Commercial License. Flux.1 [Dev] is available for use via the Civitai on-site Generator, as Model Mode: Standard. Model Weights can be downloaded from Civitai here.

- Flux.1 [Schnell] – Schnell (German for “fast”), is the equivalent of an SDXL Lightning model; fast low step-count generations at the expense of some image fidelity. Flux.1 [Schnell] is released under the Apache-2.0 License. Flux.1 [Schnell] is available for use via the Civitai on-site Generator, as Model Mode: Draft. Model Weights can be downloaded from Civitai here.

How does Flux Perform? What does it look like?
How does Flux perform? In a word; phenomenally. Described by many in the Community as “the model we’ve been waiting for”, after the disappointment of SD3, Flux has been warmly received. Image fidelity, prompt adherence, and overall image quality are exceptional, setting a new standard in the text2img landscape.


How do I make images with Flux?
Good news! You can create Flux images with the Civitai on-site Generator!
To get started, pop open the Image Generator and it will be pre-loaded! That’s right, Flux has become so popular that it’s our default model for generation!
From here you’ll be able to select a Model Mode; Draft, Standard, Pro, Pro 1.1, and Ultra. Pro, Pro 1.1, and Ultra are API-only models and will yield the best results, for a price!
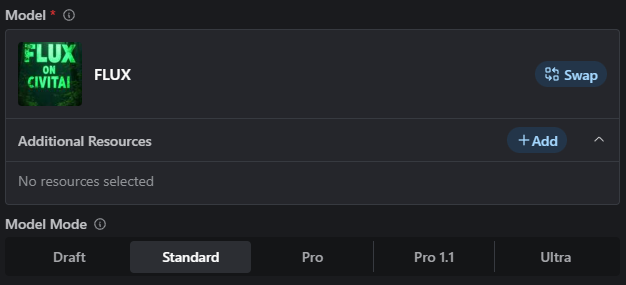
You’ll notice that the Advanced Settings for Flux are more limited than for SD1.5, SDXL or Pony Models.
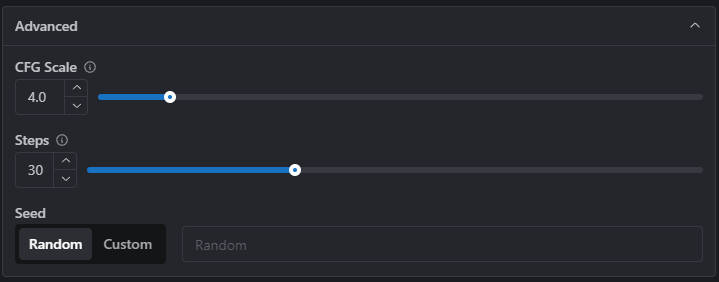
There aren’t many settings which need to be tweaked to make great Flux images, but we’ll expand these options for power users in future!

Images Generated on-site with Flux, Dev and Pro
How do I generate images locally?
Currently, there are a couple of options for local generation, depending on your hardware!
As of 9/10/2024 there is not yet official support for Flux on Automatic1111.
For the latest Flux-Automatic1111 WebUI info, keep an eye on this Issue on the official Automatic1111 Github Repository.
Since release, a number of small, cleverly optimized, Flux models have appeared, making it easier to run Flux on both ComfyUI and Forge! Details below.
ComfyUI
Flux.1 launched with day-1 ComfyUI support, making it one of the quickest and easiest ways to dive into generating with the original Black Forest Labs models.
To get started using Flux with ComfyUI, you’ll need the following components:
Original/Official Flux Models
The following models are the originals released by Black Forest Labs, and Comfyanonymous, for use in ComfyUI (and other interfaces).
| Flux.1 Models | HF Link | Civitai Link |
|---|---|---|
| ae.safetensors (vae, required) | Black Forest Labs HF Repository | |
| flux1-dev.safetensors | Black Forest Labs HF Repository | Civitai Download Link |
| flux1-schnell.safetensors | Black Forest Labs HF Repository | Civitai Download Link |
| Clip_l.safetensors | Comfyanonymous HF Repository | |
| t5xxl_fp16.safetensors | Comfyanonymous HF Repository | |
| t5xxl_fp8_e4m3fn.safetensors | Comfyanonymous HF Repository | |
| flux1-kontext-dev.safetensors (fp16) | Black Forest Labs HF Repository | Civitai Download Link |
| flux1-kontext-dev.safetensors (fp8) | Civitai Download Link | |
| flux1-Krea-dev.safetensors | Civitai Download Link |
- Note that the Flux-dev and -schnell .safetensors models must be placed into the ComfyUI/models/unet folder.
- Clip Models must be placed into the ComfyUI/models/clip folder. You may already have the required Clip models if you’ve previously used SD3.
- Some System Requirement considerations;
- flux1-dev requires more than 12GB VRAM
- flux1-schnell can run on 12GB VRAM
- If you have less than 32GB of System RAM, use the t5xxl_fp8_e4m3fn text encoder instead of the t5xxl_fp16 version.
Third-Party Flux Models
If you’re unable to run the ‘full fat’ official models, there are a number of “compressed” models available which require less VRAM to use!
Creator Kijai has released compressed fp8 versions of both flux1-dev and flux1-schnell. While there might be some reduction in image quality, these versions make it possible for users with less available VRAM to generate with Flux.
| Flux.1 Models | HF Link |
|---|---|
| flux1-dev-fp8.safetensors | Kijai HF Repository |
| flux1-schnell-fp8.safetensors | Kijai HF Repository |
You’ll also need a basic text-to-image workflow to get started. The download link below provides a straightforward setup with some solid pre-set options.
Forge
One of our favorite interfaces, Forge, (Update 7/2025 – Forge is no longer updated!) has received Flux support in a surprise Major Update! If you’re familiar with Automatic1111’s interface, you’ll be right at home with Forge; the Gradio front-ends are practically identical.
Forge can support the original Flux models, and text encoders, as listed above for Comfy.
To use the full models and text encoders, there are new fields in which the models and encoders can be loaded;

Forge creator, Illyasviel, has released a “compressed” NF4 model which is currently the recommended way to use Flux with Forge (See Quantized models, below); “NF4 is significantly faster than FP8 on 6GB/8GB/12GB devices and slightly faster for >16GB vram devices. For GPUs with 6GB/8GB VRAM, the speed-up is about 1.3x to 2.5x (pytorch 2.4, cuda 12.4) or about 1.3x to 4x (pytorch 2.1, cuda 12.1)“
| Model | HF Link |
|---|---|
| flux1-dev-bnb-nf4-v2.safetensors | Illyasviel HF Repository |
| flux1-dev-fp8.safetensors | Illyasviel HF Repository |
Note! If your GPU supports CUDA newer than 11.7 you can use the NF4 model. Most RTX3XXX and 4XXX GPUs support NF4).
If your GPU is a GTX10XX/20XX, it may not support NF4. In this case, use the fp8 model.
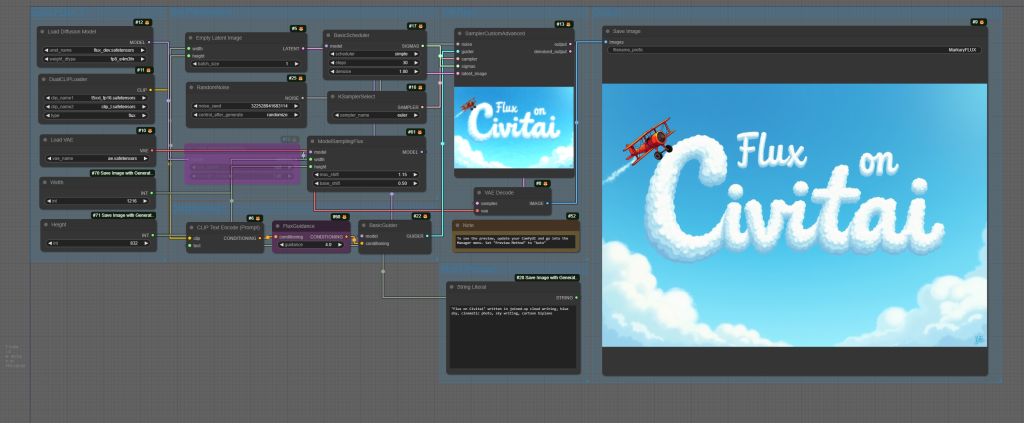
GGUF Quantized Models & Example Workflows – READ ME!
Both Forge and ComfyUI have support for Quantized models. Quantization is a technique first used with Large Language Models to reduce the size of the model, making it more memory-efficient, enabling it to run on a wider range of hardware.
There are now a range of “GGUF” (Georgi Gerganov’s Unified Format) Quantized Flux Models. GGUF-Q8 provides image outputs 99% identical to the original FP16 Flux models, while requiring almost half the VRAM!
? At time of writing, GGUF-Q8 is the preferred method for local Flux generation, for both ComfyUI and Forge, offering the best tradeoff between quality and VRAM use. GGUF-Q8 is both faster, and produces images of better quality, than the NF4 models, mentioned above.
| Model Name | Civitai Link | HF Link |
|---|---|---|
| Flux.1 Dev GGUF Q8 | Civitai Download Link | HuggingFace Download Link |
| Flux.1 Schnell GGUF Q8 | Civitai Download Link | HuggingFace Download Link |
Note that the GGUF models can be used with the ComfyUI-GGUF custom node. A Civitai created sample workflow can be found below. Use the ComfyUI manager to detect and install missing nodes in your ComfyUI installation.
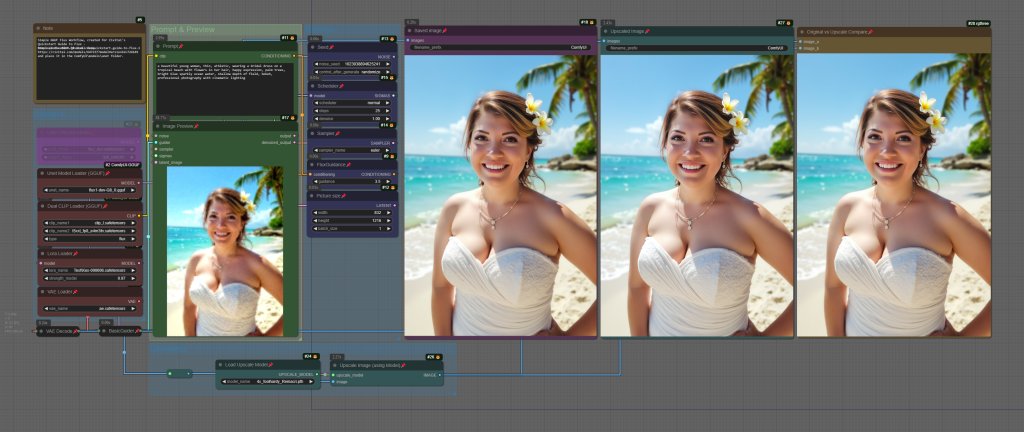
Flux Prompting
Flux image prompting tends to shine with a more verbose, natural language narrative-style prompt, rather than the traditional comma-separated ‘Danbooru’ tag style prompt. However, it’s remarkably forgiving and responds well to experimentation, making it worthwhile to test out prompts from both SD1.5 and SDXL to see what unique results you can achieve!
What truly sets Flux apart from other models is its remarkable ability to render text – not just single words, but entire sentences, with impressive clarity. This feature alone opens up a world of possibilities for creators looking to integrate text into their images!
Prompt: intricate detail, (standing stone:1.3) carved with (glowing blue text:1.2) “very old magical stone!”, very detailed, Cinematic lighting, with volumetric rays and bloom effect, dramatic lighting, clouds at sunset, photorealistic digital art trending on Artstation 8k HD high definition detailed realistic
Prompt: Ultra high quality, very detailed, A mysterious fog-shrouded landscape illuminated by a blood moon with smokey clouds, looming darkness and heavy fog, eerie feeling, very dark, deep black, deep dark shadow, dark ruined tower in distance, dim moonlight, reflections in water, spectres, shapeless evil, transylvania, wood and neon signpost in foreground with text “5 Star Hotel!”
License Considerations
The following licenses apply to the three Flux variants;
| Flux Model | License |
|---|---|
| Flux.1 [Pro] | Governed by the Flux API License. |
| Flux.1 [Dev], Flux.1 Kontext [Dev], Flux.1 Krea [Dev] | Flux.1 Dev Non-Commercial License |
| Flux.1 [Schnell] | Apache 2.0 License |
Training with Flux
Train Flux LoRA on Civitai!
Flux LoRA training is available on-site!
Here are some tips and tricks we’ve found during testing Flux training on-site;
- Mixing realistic images + cartoon training data set images makes everything look plastic and terrible!
Danbooru comma separated captioning does not seem to be effective.We’re finding that natural language captioning – narrative style – is a lot more effective for a good output. Additionally, a mix of natural language and danbooru tag style captioning has shown promising results! Note: we now have Natural Language auto-captioning available in the on-site LoRA trainer!
- We’re finding and hearing that captionless training can produce some very good, flexible, results! Try your next training session with no captions!
- Larger datasets seem much less flexible than smaller ones. We had great success with 20-30 images. With an additional 15 images the prompting flexibility was drastically reduced!
- Training with a resolution of 512 seems to produce excellent results – much better and faster than 1024x!
- Phenomenal likeness capture can be achieved with 20-40 images, ~1500 steps;
Likeness Capture
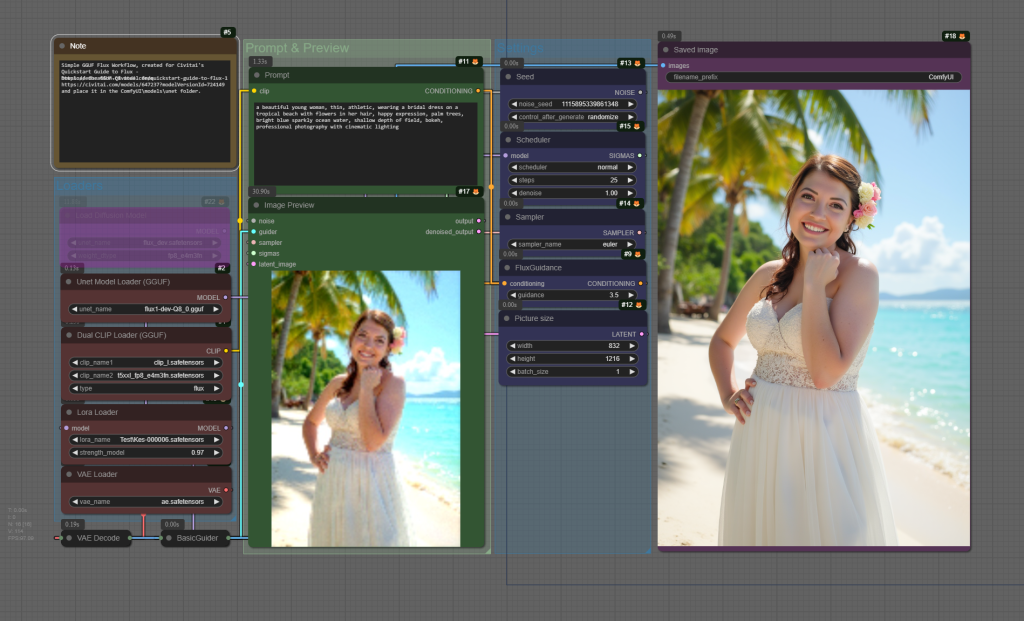
With a data set of ~30 portrait photos, an excellent, flexible, likeness LoRA can be trained (subject, one of our on-site Moderators, reproduced here with permission).

Captioned with the on-site Trainer’s Natural Language captioning tool, and trained with default Flux settings, changed only to increase repeats (10) and Epochs (12), decrease Batch Size (2), and aim for a Target Steps of 1560.
Settings changed from Default shown in bold;
{
"engine": "kohya",
"unetLR": 0.0005,
"clipSkip": 1,
"loraType": "lora",
"keepTokens": 0,
"networkDim": 2,
"numRepeats": 10,
"resolution": 512,
"lrScheduler": "cosine_with_restarts",
"minSnrGamma": 5,
"noiseOffset": 0.1,
"targetSteps": 1560,
"enableBucket": true,
"networkAlpha": 16,
"optimizerType": "AdamW8Bit",
"textEncoderLR": 0,
"maxTrainEpochs": 12,
"shuffleCaption": false,
"trainBatchSize": 2,
"flipAugmentation": false,
"lrSchedulerNumCycles": 3
}
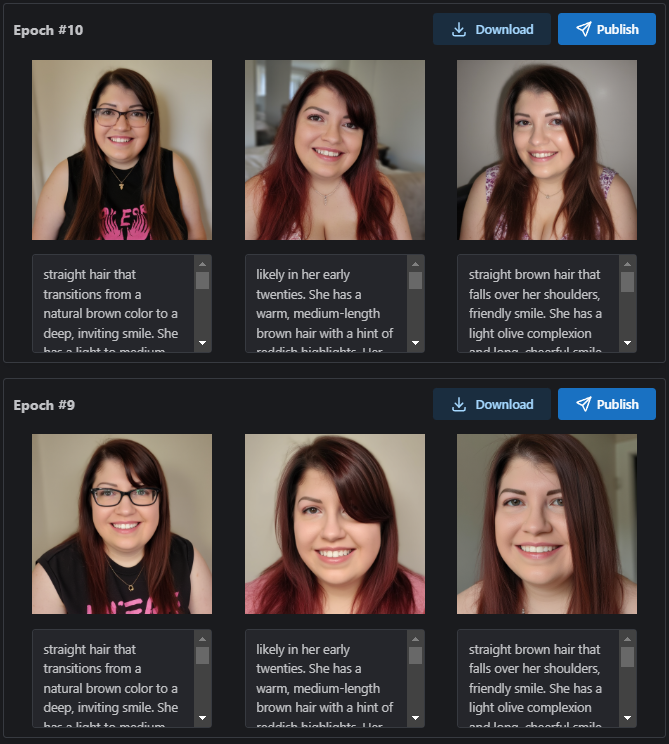
After testing, Epoch #6 offered an excellent balance of likeness capture, fidelity, and flexibility of prompting. Example images below (25 steps, 3.5 Guidance);






Remember! LoRAs trained on images of real people cannot be hosted on Civitai. Please see our Content Policies for more information.
Phenomenal examples of Flux LoRA’s trained with the Civitai on-site LoRA Trainer;





![Tangbohu wool knitted style [FLUX]](http://education.civitai.com//wp-content/uploads/2024/08/tangbohu_wool_style_FLUX_e000010_00_20240904143954.png)
Rapid Flux Training
We’re offering Rapid Flux Training – LoRAs trained in under 5 minutes! To enable this, simply check the Rapid Training toggle after selecting Flux Dev as the Base model;
Rapid Training does not accept custom Training Parameters, and outputs a single LoRA file (one Epoch) when training is complete.
Rapid Training has a base cost of 4,000 Buzz, with a data set of 100 images, with the price increasing for every 100 images added thereafter.
Using the same data set as the likeness capture example, above, a LoRA was trained and ready for use in 2 minutes and 32 seconds.
The following images demonstrate the fidelity of the output (compare to those from the “traditionally trained” LoRA, above);



Flux ControlNets?
Yes! The first Flux ControlNet models are appearing and can be used in ComfyUI! At time of writing, there are Depth, HED, and Canny models available.
| Model | Civitai Link |
|---|---|
| InstantX Canny | Civitai Link |
| Kadirnar Canny 16k | Civitai Link |
| XLabs-AI Canny | Civitai Link |
| XLabs-AI Depth | Civitai Link |
| XLabs-AI HED | Civitai Link |
| XLabs-AI IP Adapter | Civitai Link |
Below are simple Civitai-created ControlNet workflows based upon the XLabs ControlNet models;
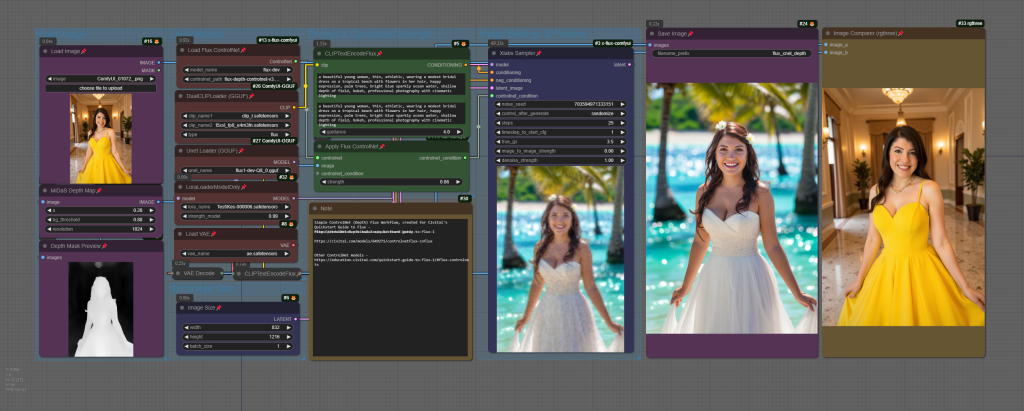
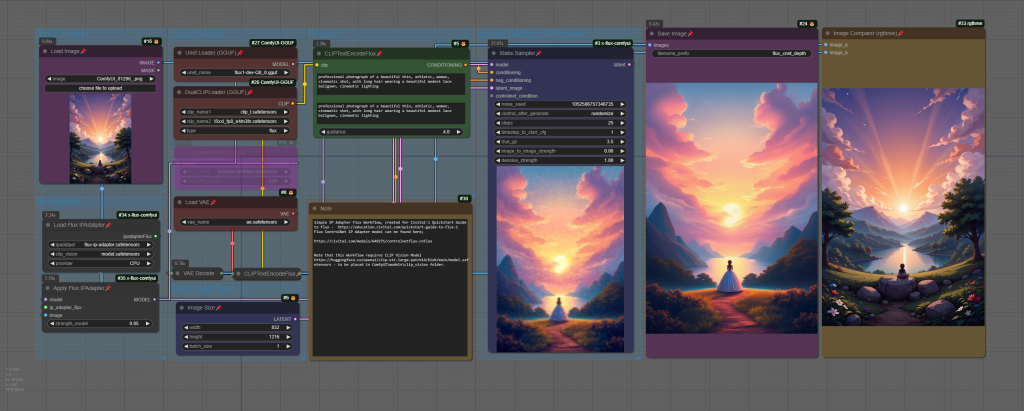
Train Flux locally with Kohya and X-Flux
More good news for creators: Flux allows for both LoRA training and full finetuning on consumer hardware! With tools like X-Flux from XLabs and Kohya, you can embark on LoRA training, though it’s worth noting that this process is still in its early stages, and hardware requirements remain quite steep.
To train a LoRA against the Flux Dev model, you’ll need an NVIDIA RTX3000 or 4000 Series GPU with at least 24 GB of VRAM.
Even more impressively, according to reports from the Kohya GitHub repository, full BF16 finetuning (without the need for quantization or fp8) can be achieved with just 24GB of VRAM. This development marks a significant breakthrough, making advanced training more accessible than ever before;
The Flux landscape is rapidly evolving, with tens of GitHub commits daily as new features and improvements are discovered and implemented, so stay tuned for more updates!
Flux Tools
On 11/21/2024 Black Forest Labs released a suite of models titled Flux Tools, designed to enhance the capabilities of the Flux models. Think “ControlNet”, for Flux. The Flux Tools are released under the Flux.1-dev Non-Commercial License.
ComfyUI has support, but most models are so large they’ll only fit on the largest consumer graphics cards, requiring 24GB of VRAM. Quantized versions will appear soon!
| Model | Description | Civitai Link |
|---|---|---|
| Flux.1 Fill | State-of-the-art inpainting and outpainting model, enabling editing and expansion of real and generated images given a text description and a binary mask. | Civitai |
| Flux.1 Depth Dev | Models trained to enable structural guidance based on a depth map extracted from an input image and a text prompt. | Civitai |
| Flux.1 Depth Dev LoRA | Lightweight LoRA extracted from Depth Dev. | Civitai |
| Flux.1 Canny Dev | Models trained to enable structural guidance based on canny edges extracted from an input image and a text prompt. | Civitai |
| Flux.1 Canny Dev LoRA | Lightweight LoRA extracted from Canny Dev. | Civitai |
| Flux.1 Redux Adapter | An IP adapter that allows mixing and recreating input images and text prompts. | Civitai |
Flux.1 Fill
Download the flux1-fill-dev.safetensors model file and put it in your ComfyUI/models/diffusion_models/ folder. Load an image into the image upload node, then right click on it and select “Open in MaskEditor” to launch the inpaint interface.
A note on Inpainting and Outpainting workflows
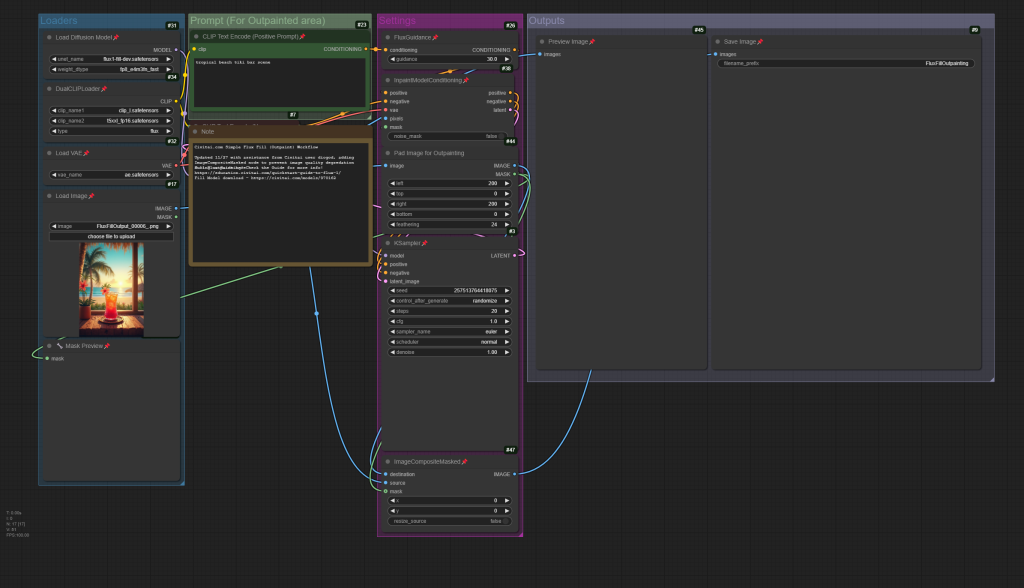
The workflows below have been updated with input from Civitai Creator diogod, who, correctly pointed out that they were missing an ImageCompositeMasked node, which prevents the entire image from degrading during in/outpainting! Huge thanks to diogod for that callout!
Additionally, we’ve added a GrowMaskWithBlur node which requires a third-party node pack – you can install missing nodes from the ComfyUI manager – which will ensure the painted mask is feathered to blend with the original image.



Example ComfyUI Flux Fill Inpainting workflow;
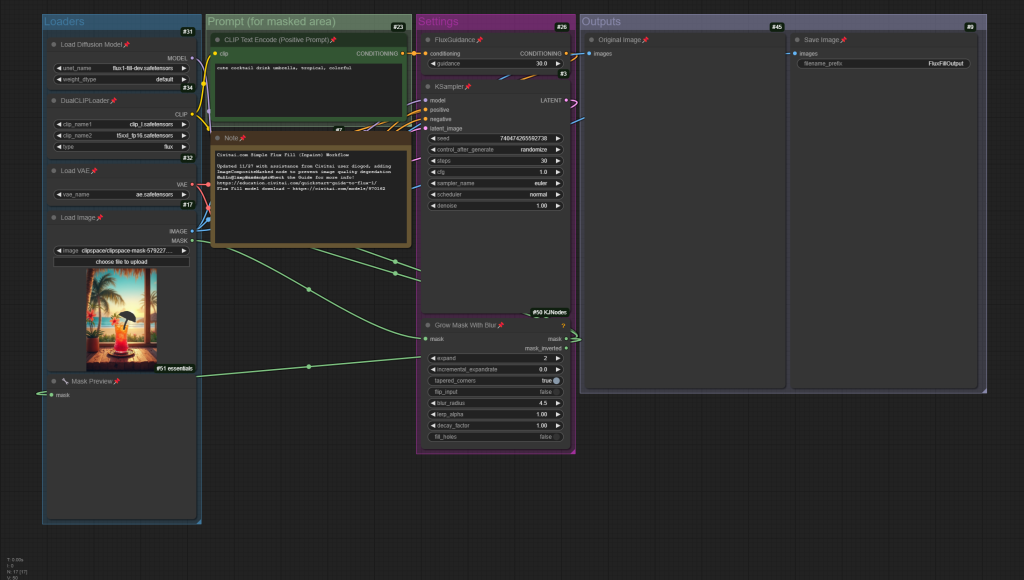
Example ComfyUI Flux Fill Outpainting workflow;
Flux.1 Redux
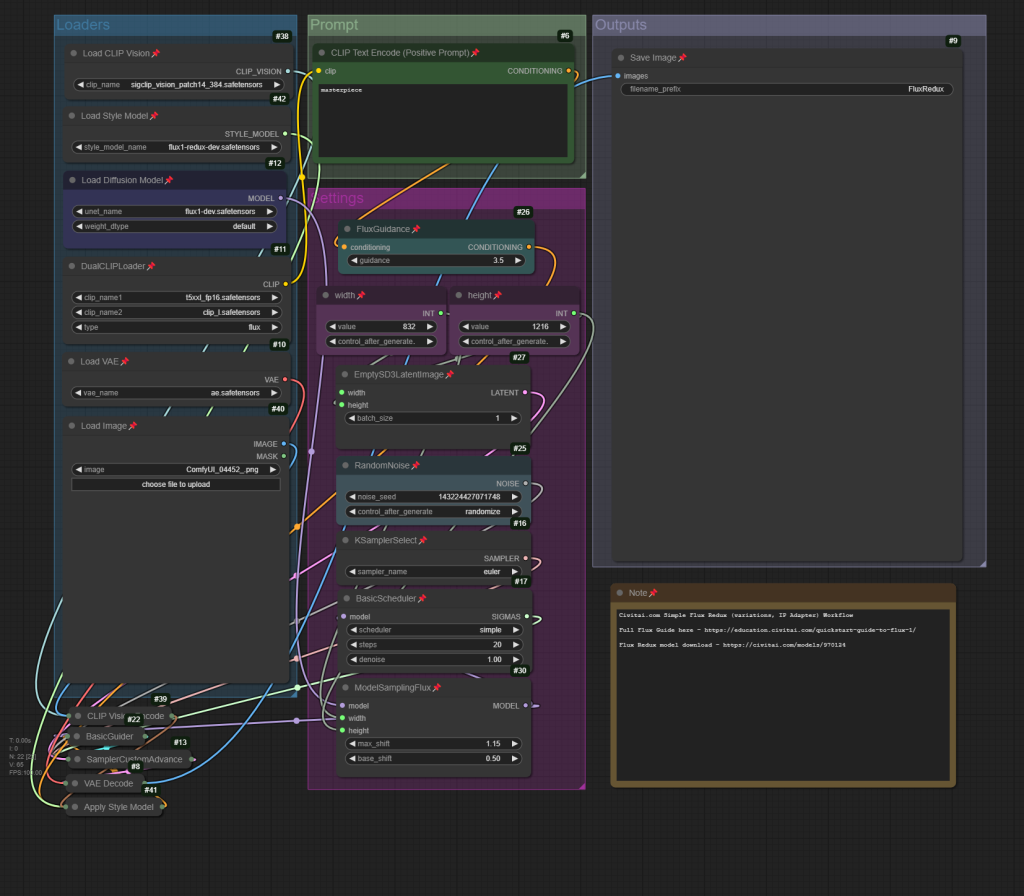
Flux Redux acts like an IP Adapter – transferring image details from one image to another. To get started, you’ll need Comfy-Org’s sigclip_vision_384 model, which must be placed in the ComfyUI/models/clip_vision folder, and also the flux1-redux-dev.safetensors file, to be placed in the ComfyUI/models/style_models folder.
Redux is excellent at creating image variations, and can be chained to combine details of multiple input images.
Example ComfyUI Flux Redux workflow;
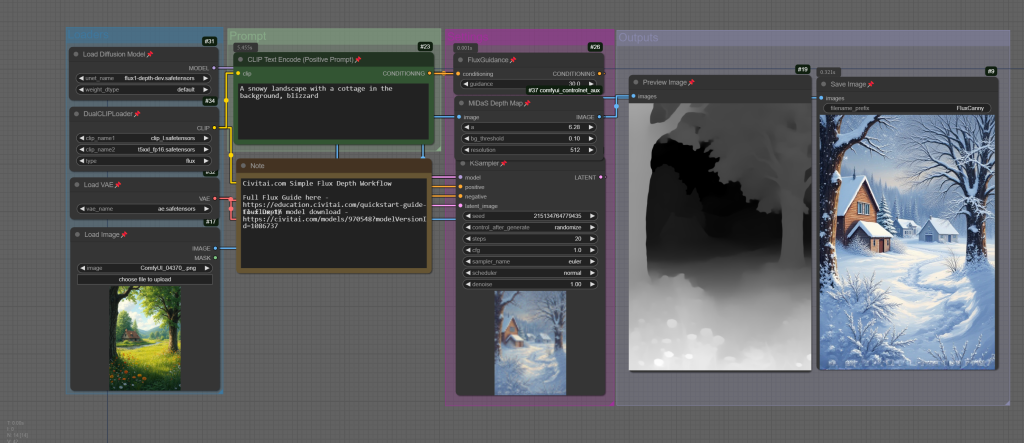
Flux Depth & Canny “ControlNet” Models
Flux Tools includes two “ControlNet” like models, Canny and Depth. Place them in the ComfyUI/models/diffusion_models/ folder.
Canny looks for edges in an input image, allowing the style of the image to be changed while retaining the overall structure.



Flux.1 Kontext
In mid 2025 Black Forest Labs released Flux.1 Kontext, a state-of-the-art multimodal model allowing edits to images using both text prompts and image inputs, making it possible to perform precise, context-aware modifications without losing the fidelity of the input image.
There are three Flux Kontext models – two of which can be used on Civitai’s Generator, and one which can be used locally;
- FLUX.1 Kontext [pro] – A pioneer for fast, iterative image editing. A single model that delivers local editing, generative in-context modifications and classic text-to-image generation in signature FLUX.1 quality. FLUX.1 Kontext [pro] handles both text and reference images as inputs, seamlessly enabling targeted, local edits in specific image regions and complex transformations of entire scenes. Operating up to an order of magnitude faster than previous state-of-the art models, FLUX.1 Kontext [pro] is a pioneer for iterative editing, since it’s the first model that allows users to build upon previous edits through multiple turns, while maintaining characters, identities, styles, and distinctive features consistent across different scenes and viewpoints.
- FLUX.1 Kontext [max] – Maximum Performance at High Speed. Our new experimental model greatly improves prompt adherence and typography generation, and high consistency for editing. All these without compromise on speed.
- FLUX.1 Kontext [dev] – A 12B parameter open-source version, suitable for local research usage.

Using Flux.1 Kontext on Civitai
Navigate to the Flux.1 Kontext Civitai model, or find it in the Model Swap/Picker.
Flux.1 Kontext has two modes, both powered by the Black Forest Labs API – Pro and Max, corresponding to the Pro and Max models (details above).
Note that you will need to provide a starting image before generating!
Use natural language in the Prompt box, to describe changes you’d like to see made to your input image, such as;




Flux.1 Krea [Dev]
Details to follow!
Any Other Details?
- This guide is a living document and will evolve over time. Everything Flux-related is advancing at an incredible pace, with today’s pertinent details potentially being outdated by tomorrow. For the most up-to-date information and guidance from our Community experts, be sure to join the Civitai Discord server!
