First version! This document will be kept up to date with SDXL developments!
8/1/2023
1.2
Automatic1111 Refiner Extension
8/3/2023
1.2
Training SDXL
What is SDXL 1.0?
SDXL 1.0 is a groundbreaking new text-to-image model, released on July 26th. A precursor model, SDXL 0.9, was available to a limited number of testers for a few months before SDXL 1.0’s release.
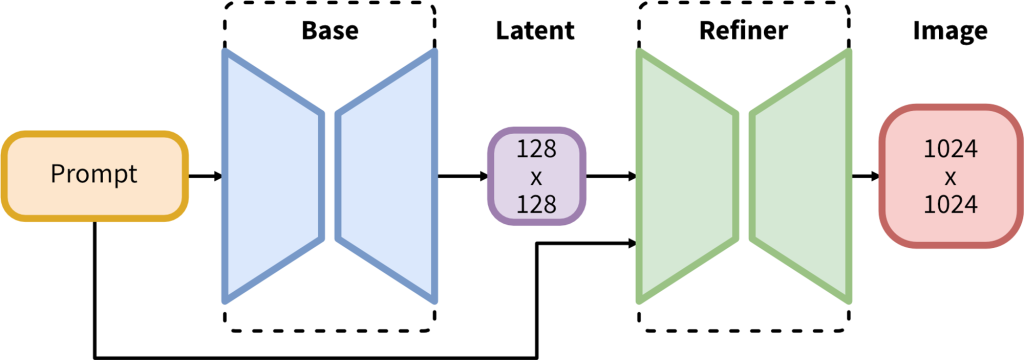
Technologically, SDXL 1.0 is a leap forward from SD 1.5 or 2.x, boasting a parameter count (the sum of all the weights and biases in the neural network that the model is trained on) of 3.5 billion for the base model and a 6.6 billion for the second stage refiner. In contrast, SD 1.4 has just ~890 million parameters. Further information about the inner workings of SDXL can be found on Stability AI’s SDXL research paper here;
Aside from ~3x more training parameters than previous SD models, SDXL runs on two CLIP models, including the largest OpenCLIP model trained to-date (OpenCLIP ViT-G/14), and has a far higher native resolution of 1024×1024, in contrast to SD 1.4/5’s 512×512, allowing for greatly improved fidelity and depth.
Unlike previous SD models, SDXL uses a two-stage image creation process. The base model generates the initial latent image (txt2img), before passing the output and the same prompt through a refiner model (essentially an img2img workflow), upscaling, and adding fine detail to the generated output.
What does all that mean for image generation?
The most immediately apparent difference between SDXL and previous SD models is the range and depth of output in photorealistic images.
In short; quality, depth, lighting, flexibility, and fidelity.
It also performs exceptionally well when creating images with complex lighting.
It’s extremely flexible in style, and prompts are followed with much greater accuracy and coherency than previous SD iterations.
True-black shadows are achievable, as the model has in-built noise-offset.
Where do we get it?
The base model, refiner, and vae are all hosted on Civitai.com
Automatic1111 WebUI – At time of writing (8/17), A1111 has SDXL support, but the VRAM and RAM requirements are extremely high. In testing, a 1024×1024 image used ~11.4 GB of VRAM.
? If running WebUI with <10 GB VRAM it’s recommended to use the startup arguments –medvram or –lowvram – image generation will be slow!
Vladmandic Fork – Vlad’s fork of SDXL has full base and refiner model support, and doesn’t seem to suffer from the high VRAM requirements of A1111.
InvokeAI – InvokeAI’s 3.0 release has full SDXL support.
StableSwarmUI – A new UI from Stability AI, with native SDXL support and distributed computing architecture components, allowing multi-gpu inference. Also available on Colab.
Hardware Requirements
The official Stability requirements for local inference (generating images) are 16 GB of system RAM, and an RTX 20XX GPU with a minimum of 8GB of VRAM. Linux users may also use a compatible AMD card with 16 GB of VRAM.
Training requirements are a little harder to pin down, but we have confirmation from Stability that LoRA can be trained on an RTX 2070 with 8GB of VRAM. With an input resolution of 768x, training used 7.1 GB of VRAM and took ~30 minutes.
Note: Despite Stability’s findings on training requirements, I have been unable to train on < 10 GB of VRAM.
Training at full 1024x resolution used 7.8 GB of VRAM and 2000 steps took approximately 1 hour.
Local Interfaces for SDXL
At time of writing, the favored interface for SDXL inference is ComfyUI. The author of ComfyUI is now a Stability employee, and as such, ComfyUI has been recommended as the UI of choice. It’s fast, modular, and extremely flexible, but can be daunting for first-time users.
Automatic1111 WebUI + Refiner Extension
Automatic1111’s support for SDXL and the Refiner model is quite rudimentary at present, and until now required that the models be manually switched to perform the second step of image generation.
WCDE has released a simple extension to automatically run the final steps of image generation on the Refiner model, removing the need to switch models or perform an img2img!
Unfortunately, VRAM requirements for this operation are still extremely high, and the recommendation is to use use Tiled VAE if you have 12GB or less VRAM.
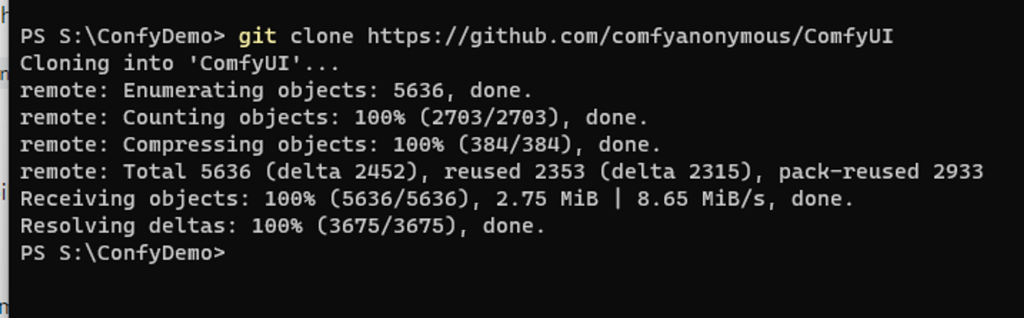
Download the ComfyUI zip and extract into a folder on your local PC. If you have Git for windows installed (the best method), you can pull the repository down with;
But since we’re all using Torch 2.0, you can also run ComfyUI with Pytorch sdp-cross-attention activated, which may boost your iterations per second (image generation speed)
Note – if you get the common Torch not compiled with CUDA enabled error, follow these directions;
Ensure (venv) is still activated – if not, enable it by running the Venv Activate script again.
Run pip uninstall torch
Run pip install torch torchvision torchaudio –extra-index-url https://download.pytorch.org/whl/cu118 xformers
Re-launch the interface with python main.py
Model files, SDXL or otherwise, should be placed within the ComfyUI/models/checkpoints folder. VAE files within the ComfyUI/models/vae folder.
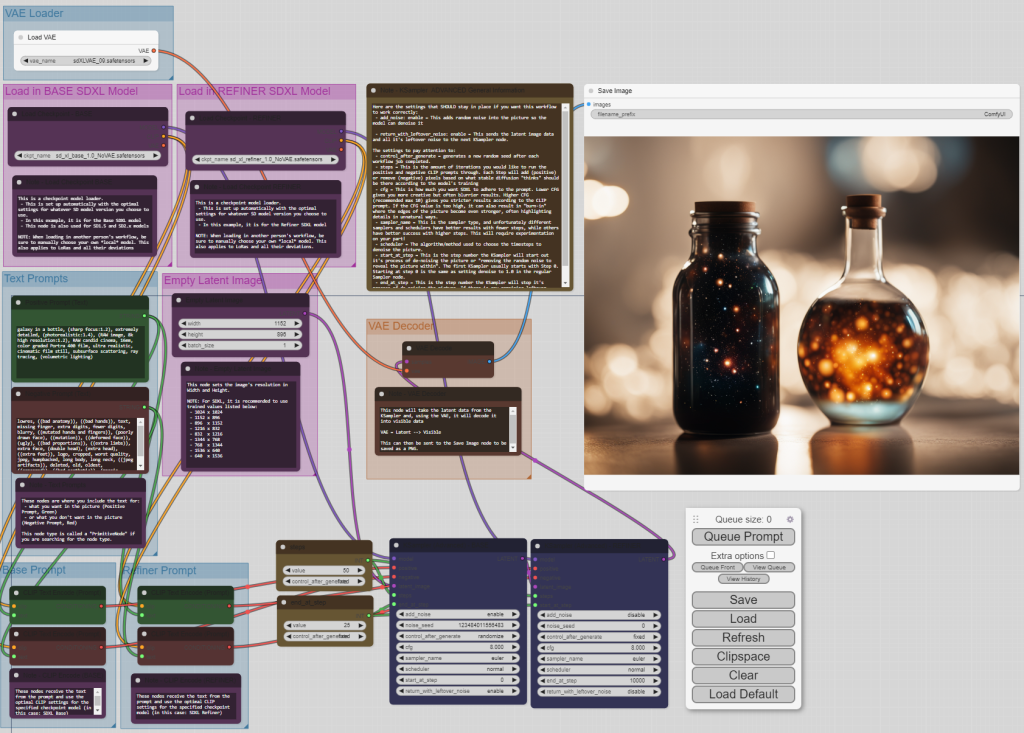
Generating images with ComfyUI for SDXL is a little tricky!
A number of Official and Semi-Official “Workflows” for ComfyUI were released during the SDXL 0.9 testing phase. These still work for SDXL 1.0, but Stability AI’s Joe Penna released a new “Official” ComfyUI workflow which is easy to follow, contains a lot of tips and usage information, and most importantly, produces beautiful results!
Immediately after 1.0’s July 26th release it was apparent that Stability had changed the model somewhat from the 0.9 version, and images now had quite significant “rainbow” artifacts.
It was quickly established that the new SDXL 1.0 VAE was the culprit. There has been no official word on why the SDXL 1.0 VAE produces these artifacts, but we do know that by removing the baked in SDXL 1.0 VAE and replacing it with the SDXL 0.9 VAE, the images are much clearer/sharper.
Prompting for SDXL 1.0
One of the most significant challenges facing users who are used to prompting SD 1.5 is that of prompt composition. Many users using SDXL for the first time are shocked at how “terrible” it is. This is because it doesn’t respond well to certain tokens we’ve become accustomed to over the past few months. Danbooru tags, and long comma, separated, strings, highly detailed, masterpiece, award winning photo, intricate, (heavily weighted:1.6) style prompts are out!
Short, snappy, Midjourney-style prompts are in! The SDXL 1.0 base model is phenomenally good at interpreting and understanding what we want in our prompts, and gets wonderful results from extremely simple prompts.
Before everyone goes wild and start throwing things, yes, there are good 1.5 prompts which work well when copied over to SDXL, but more often than not you’ll have far greater success re-writing, or reformatting, prompts for SDXL.
An original prompt running on an SD 1.5 based model
beautiful woman in a white dress blowing in the wind, walking on a stormy beach, dark clouds, (cowboy shot:1.4), realistic, masterpiece, highest quality, backlighting, (lens flare:1.1), (bloom:1.1), (chromatic aberration:1.1), by Jeremy Lipking, by Antonio J. Manzanedo, digital painting
The same prompt in SDXL. Note that “cowboy shot” has been taken quite literally – one example of the differences in interpretation between 1.5 and SDXL.
A refined SDXL prompt;
a beautiful woman in a white dress, blowing in the wind, walking on a stormy beach, dark clouds, cinematic
Less can be more! ultra detailed 8k cg, japanese ramen, chopsticks, egg, steam, food photography, shallow depth of field, realism
Try extremely simple, no modifier prompts! a set of magical potions with magical properties that can be used to heal someone
Stability AI’s Joe Penna tip: Don’t use negative prompts for SDXL unless there’s something appearing in your image you don’t wish to see – and even then – give it a low (strength:0.4) to start with, working higher until it is removed.
Training SDXL
Training LoRA for SDXL 1.0 is generally more forgiving than training 1.5 based LoRA, and good results are quite easy to obtain, however the hardware requirements to do so are a lot higher than we were hoping! Read our Training Overview for more information on how to get started Training against SDXL!