

| Last Updated | Changes |
| 11/24/2023 | First version published |
| 11/28/2023 | New ComfyUI Workflows |
| 2/6/2024 | SVD 1.1 Released |
What is Stable Video Diffusion (SVD)?
Stable Video Diffusion (SVD) from Stability AI, is an extremely powerful image-to-video model, which accepts an image input, into which it “injects” motion, producing some fantastic scenes.
SVD is a latent diffusion model trained to generate short video clips from image inputs. There are two models. The first, img2vid, was trained to generate 14 frames of motion at a resolution of 576×1024, and the second, img2vid-xt is a finetune of the first, trained to generate 25 frames of motion at the same resolution.
The newly released (2/2024) SVD 1.1 is further finetuned on a set of parameters to produce excellent, high-quality outputs, but requires specific settings, detailed below.
The official Stability AI SVD release page can be found here.
Why should I be excited by SVD?
SVD creates beautifully consistent video movement from our static images!
How can I use SVD?
ComfyUI is leading the pack when it comes to SVD image generation, with official SVD support! 25 frames of 1024×576 video uses < 10 GB VRAM to generate.
It’s entirely possible to run the img2vid and img2vid-xt models on a GTX 1080 with 8GB of VRAM!
There’s still no word (as of 11/28) on official SVD support in Automatic1111.
If you’d like to try SVD on Google Colab, this workbook works on the Free Tier; https://github.com/sagiodev/stable-video-diffusion-img2vid/. Generation time varies, but is generally around 2 minutes on a V100 GPU.
You’ll need to download one of the SVD models, from the links below, placing them in the ComfyUI/models/checkpoints directory.
| Model | Civitai Link | Original Author Link |
|---|---|---|
| img2vid | Link | HF Link |
| img2vid-xt | Link | HF Link |
| img2vid-xt-1.1 (latest, see below for settings) | Link | HF Link |
After updating your ComfyUI installation, you’ll see new nodes for VideoLinearCFGGuidance and SVD_img2vid _Conditioning. The Conditioning node takes the following inputs;
| Setting | Description |
|---|---|
| video frames | The number of frames of motion to generate. |
| motion_bucket_id | The higher the number, the more motion will be in the output. |
| fps | Higher FPS results in less choppy video output |
| augmentation level | The amount of noise added to the input image. Higher noise will decrease the video’s resemblance to the input image, but will result in greater motion. |
| VideoLinearCFGGuidance | Improves sampling for video by scaling the CFG across the frames – frames farther away from the initial image frame receive a gradually higher CFG value. |
You can download ComfyUI workflows for img2video and txt2video below, but keep in mind you’ll need to have an updated ComfyUI, and also may be missing additional nodes for Video. I recommend using the ComfyUI Manager to identify and download missing nodes!
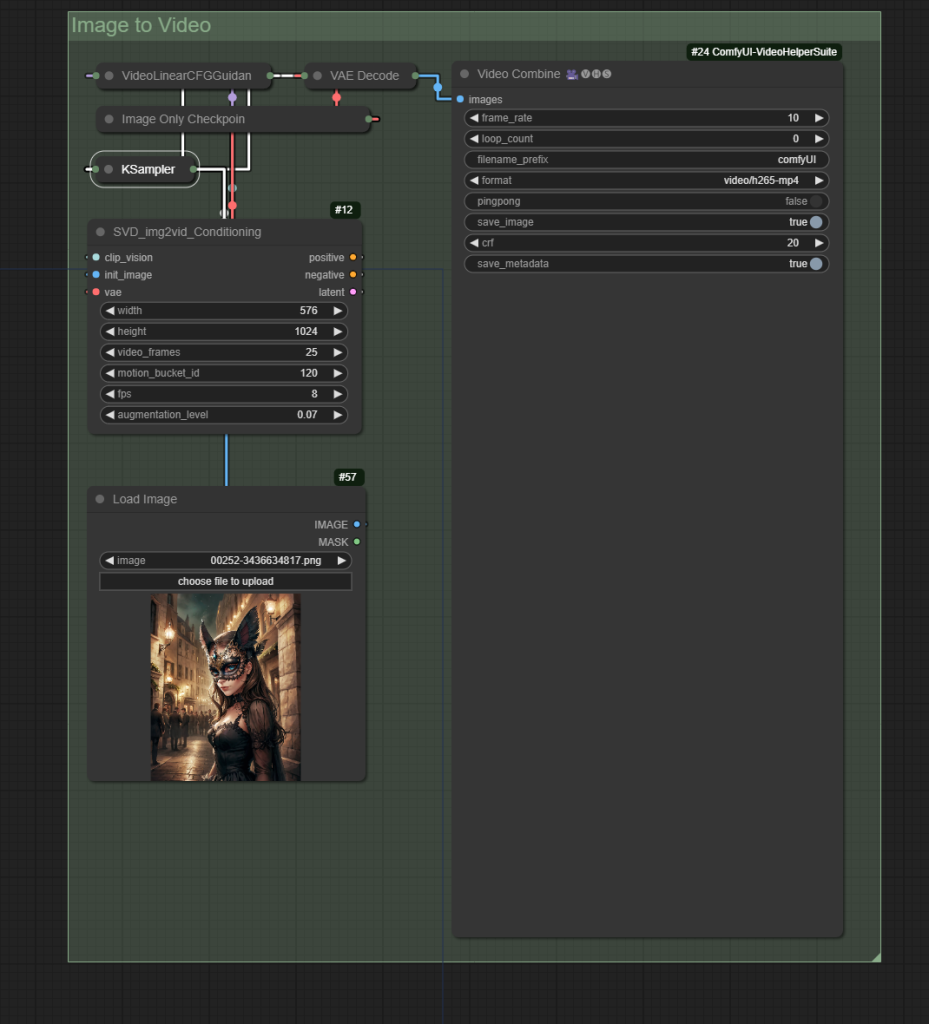
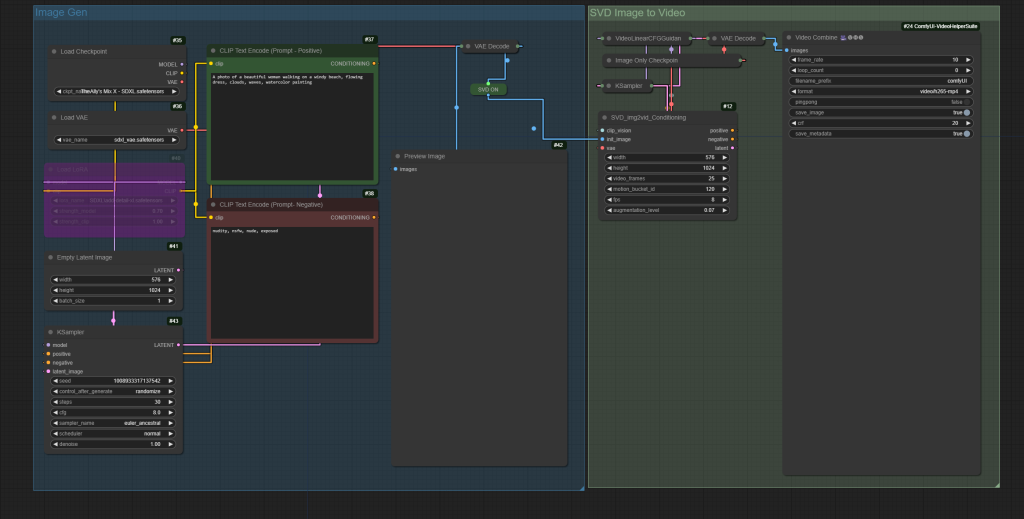
Suggested Settings
The settings below are suggested settings for each SVD component (node), which I’ve found produce the most consistently useable outputs, with the img2vid and img2vid-xt models.
| Node | Setting | Value |
|---|---|---|
| VideoLinearCFGGuidance | min_cfg | 1 |
| KSampler | Steps | 25 |
| KSampler | CFG | 2.9 |
| SVD_img2vid_Conditioning | Width | 576 |
| SVD_img2vid_Conditioning | Height | 1024 |
| SVD_img2vid_Conditioning | Video Frames | 25 |
| SVD_img2vid_Conditioning | Motion Bucket ID | 60 |
| SVD_img2vid_Conditioning | FPS | 8 |
| SVD_img2vid_Conditioning | Augmentation Level | 0.07 |
Settings – Img2vid-xt-1.1
February 2024 saw the release of a finetuned SVD model, version 1.1. This version only works with a very specific set of parameters to improve the consistency of outputs. If using the Img2vid-xt-1.1 model, the following settings must be applied to produce the best results;
| Node | Setting | Value |
|---|---|---|
| SVD_img2vid_Conditioning | Width | 1024 |
| SVD_img2vid_Conditioning | Height | 576 |
| SVD_img2vid_Conditioning | Video Frames | 25 |
| SVD_img2vid_Conditioning | Motion Bucket ID | 127 |
| SVD_img2vid_Conditioning | FPS | 6 |
| SVD_img2vid_Conditioning | Augmentation Level | 0.00 |
Output Examples (img2vid-xt-1.1)
Output Examples (img2vid-xt – v1.0)
Limitations
It’s not perfect! Currently there are a few issues with the implementation, including;
- Generations are short! Only <=4 second generations are possible, at present.
- Sometimes there’s no motion in the outputs. We can tweak the conditioning parameters, but sometimes the images just refuse to move.
- The models cannot be controlled through text.
- Faces, and bodies in general, often aren’t the best!
The Future
We’ll continue to expand this quickstart guide with more information as it becomes available, and we’ll create a full, advanced, usage guide, soon!
