

| Last Updated | Changes |
| 11/25/2024 | First Version |
| 12/19/2024 | New img2video workflow & Prompt-Enhancing GPT! |
| 12/19/2024 | New LTXV Version – 2b 0.9.1! |
| 2/5/2024 | Lightricks on the Civitai Generator! |
| 3/6/2025 | New LTXV Version – 2b 0.9.5! |
Lightricks LTXV?
Update! Lightricks is available in text-to-video and image-to-video modes on the Civitai Generator!
Lightricks LTXV is a state-of-the-art DiT-based video generation model, designed to produce exceptionally high-quality and cohesive videos. It supports both text-to-video and image-to-video workflows, delivering results at a smooth 24 frames per second and a resolution of 768×512.
One of the model’s standout features is its efficiency. Remarkably, it can generate videos with just 8GB of VRAM (*anecdotal!), making it accessible to a wide range of users. For those equipped with higher-end hardware, such as GPUs with 16GB or more VRAM, the generation process is impressively fast, taking as little as 8–10 seconds per video. This combination of quality, speed, and resource efficiency makes Lightricks LTXV a powerful tool new tool in the Generative AI video space!
Read on for examples, and our guide to getting started with ComfyUI (which has native support!)
Output Examples
text2video
img2video
LTXV in Civitai’s Generator
LTXV is available for use in the Civitai Video Generator! The following videos are examples of what can be generated on-site;
image-to-video, no prompt
Image-to-video, no prompt
text-to-video
Prompt: A woman with blonde hair styled up, wearing a black dress with sequins and pearl earrings, looks down with a sad expression on her face. The camera remains stationary, focused on the woman’s face. The lighting is dim, casting soft shadows on her face. The scene appears to be from a movie or TV show.
Local Generation with LTXV
Required Files
You’ll need one version of the Lightricks LTXV model, and a Clip Text Encoder – you may already have this if you’ve previously dabbled in Flux or SD3. Both files are available on Civitai.
| Model | Download Location | Download Source |
|---|---|---|
| Lightricks LTXV 2b v0.9.5 (Latest) | ComfyUI\models\checkpoints | Civitai |
| Lightricks LTXV 2b v0.9.1 | ComfyUI\models\checkpoints | Civitai |
| Lightricks LTXV 2b v0.9 | ComfyUI\models\checkpoints | Civitai |
| t5xxl_fp16 Clip Text Encoder | ComfyUI\models\clip | Civitai |
ComfyUI Basic Workflows
ComfyUI added native LTXV support in late November, allowing anyone with a consumer GPU to generate locally, without any extra LTXV node downloads.
- Update ComfyUI to the latest version which includes LTXV Support
- Download the weights (see above)
- Download a text encoder (see above)
- Download and load the example workflow (see below) – plug in the models – and start generating!
Workflows (Model version 0.9.5 – Latest Model)
On March 6th 2025, LTXV Version 0.9.5 released with a whole range of cool new features – including higher quality outputs, less artifacting, and longer generations!
Unfortunately, the new model requires new Workflows! We’ve put together some simple flows for 0.9.5 Text-to-Video and Image-to-Video, and will be exploring the more advanced flows soon!
To download the workflows below, you may have to right click and “Save link as…”



Sample Workflows (Model version 0.9.1 & older)
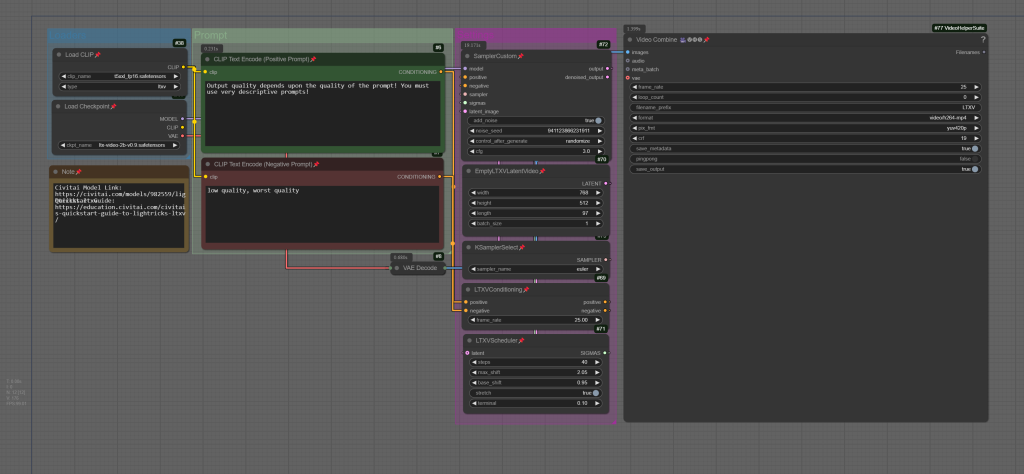
Simple text2video workflow. Note; requires Video Combine node, part of the Video Helper Suite
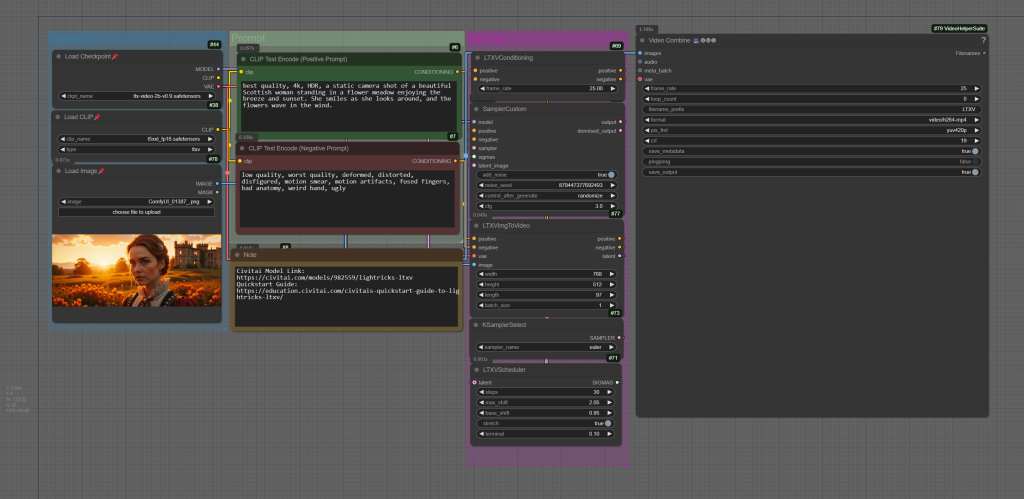
Simple img2video workflow. Note; requires Video Combine node, part of the Video Helper Suite
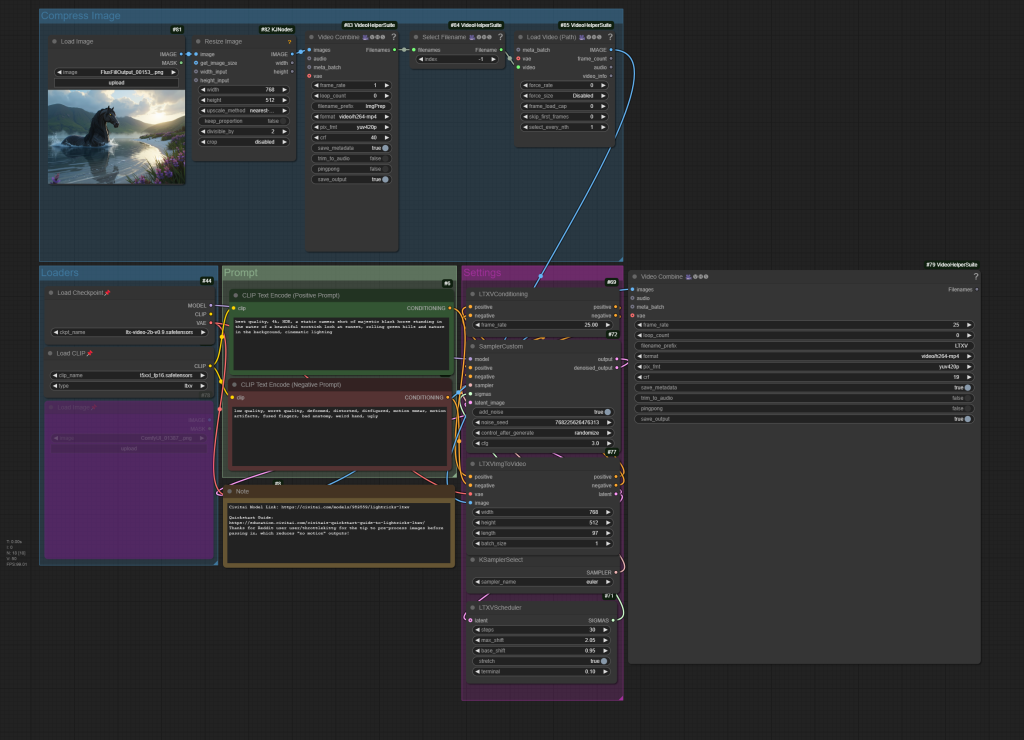
It turns out that LTXV doesn’t particularly like “clean”, high-resolution input images, and can often produce videos with no motion when those are passed in. To combat this, it helps to add some compression to the input image prior to it being passed in to LTXV. The following workflow automates that process, resulting in far fewer “no motion” outputs;
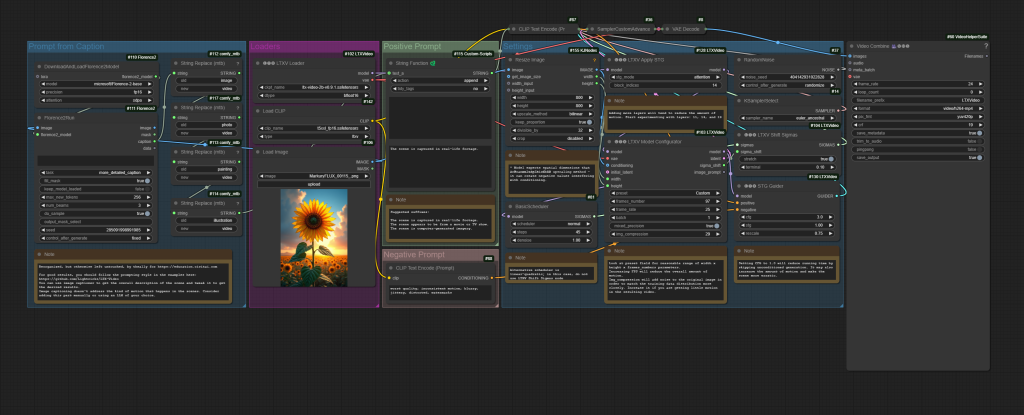
ComfyUI Advanced Workflows (Model version 0.9.1, & older)
The following workflows, released by Lightricks, require the LTXV ComfyUI node-pack to function. These workflows work with the latest 2b 0.9.1 model and offer a number of improvements in consistency, and quality! They integrate Microsoft’s Florence2 vision model, for prompt enhancement (in the case of text-to-video) and automated prompt generation (in the case of image-to-video).
Interestingly, the latest 2b 0.9.1 model is a whopping 4 gigabytes smaller than the 0.9 version, but still manages to produce phenomenal results – especially with image-to-video – in ~30-40 seconds on an RTX 4090;
The best way to install the LTXV custom nodes is from the ComfyUI Manager;

Once all the required node-dependencies are installed – use the ComfyUI manager to resolve any missing node warnings – you can simply add a short prompt (text-to-video), or drop an initial image (image-to-video), and the generation process can begin!
The following Workflows are official Lightricks creations, which have been re-organized and grouped for clarity, but otherwise unedited. If you’d prefer to use the originals, they can be found here (text-to-video) and here (image-to-video).
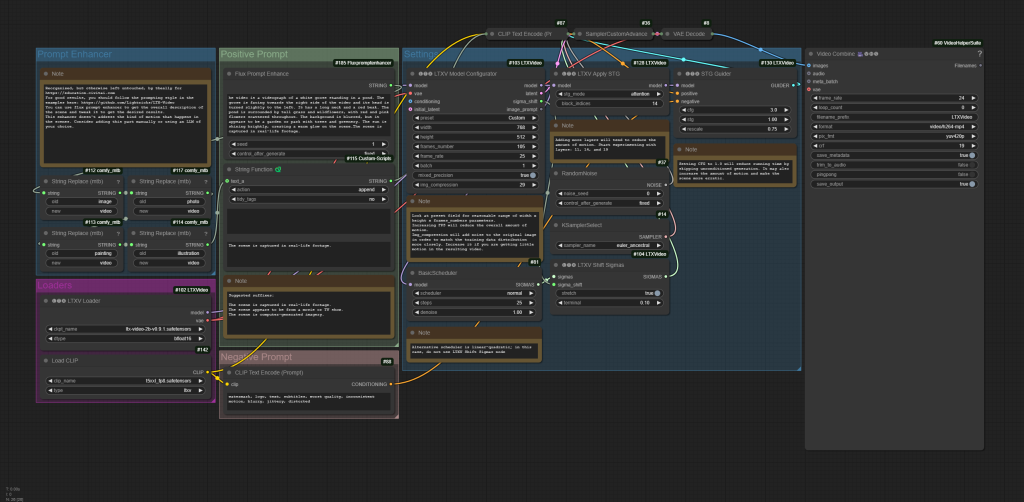
Prompting
Note! If you’re using image-to-video, try leaving the prompt box blank!
The workflow includes a vision model which will automatically write and apply a relevant prompt to any image passed into image-to-video!
You may want to add watermark, logo to the negative prompt to reduce the probability of those appearing in your outputs!
Don’t skimp on prompting with LTXV! When working with text-to-image LTXV the golden rule is this: The quality of your outputs is only as good as the quality of your inputs. Skimping on prompts – providing vague or minimal instructions – will lead to underwhelming results, leaving you wondering why the output doesn’t meet your expectations. To unlock the full potential of LTXV, it’s essential to master the art of descriptive prompting. From the Lightricks Github;
Focus on detailed, chronological descriptions of actions and scenes. Include specific movements, appearances, camera angles, and environmental details – all in a single flowing paragraph. Start directly with the action, and keep descriptions literal and precise. Think like a cinematographer describing a shot list. Keep within 200 words. For best results, build your prompts using this structure:
- Start with main action in a single sentence
- Add specific details about movements and gestures
- Describe character/object appearances precisely
- Include background and environment details
- Specify camera angles and movements
- Describe lighting and colors
- Note any changes or sudden events
If you’re having trouble writing descriptive prompts, try our Prompt-Enhancing GPT!
Example prompts;
A woman with blood on her face and a white tank top looks down and to her right, then back up as she speaks. She has dark hair pulled back, light skin, and her face and chest are covered in blood. The camera angle is a close-up, focused on the woman's face and upper torso. The lighting is dim and blue-toned, creating a somber and intense atmosphere. The scene appears to be from a movie or TV show.A woman with blonde hair styled up, wearing a black dress with sequins and pearl earrings, looks down with a sad expression on her face. The camera remains stationary, focused on the woman's face. The lighting is dim, casting soft shadows on her face. The scene appears to be from a movie or TV show.
A clear, turquoise river flows through a rocky canyon, cascading over a small waterfall and forming a pool of water at the bottom.The river is the main focus of the scene, with its clear water reflecting the surrounding trees and rocks. The canyon walls are steep and rocky, with some vegetation growing on them. The trees are mostly pine trees, with their green needles contrasting with the brown and gray rocks. The overall tone of the scene is one of peace and tranquility.
Parameters
- Resolution Preset: Higher resolutions for detailed scenes, lower for faster generation and simpler scenes. The model works on resolutions that are divisible by 32 and number of frames that are divisible by 8 + 1 (e.g. 257). In case the resolution or number of frames are not divisible by 32 or 8 + 1, the input will be padded with -1 and then cropped to the desired resolution and number of frames. The model works best on resolutions under 720 x 1280 and number of frames below 257
- Guidance Scale: 3-3.5 are the recommended values
- Inference Steps: More steps (40+) for quality, fewer steps (20-30) for speed
Limitations
- Licensing! LTXV uses the Rail-M license, full text available here.
I need more help!
If you’re experiencing issues generating Video with the Civitai Generator and a solution isn’t mentioned on this page, please reach out to our Support team at [email protected]. If you’re having trouble setting up LTXV for local generation, please join the Civitai Discord and seek assistance in the #ai-help channel!
