

| Last Updated | Changes |
| 11/14/2024 | First Version |
| 1/15/2025 | Bring Your Own Image – Img2Video From Any Image! |
| 8/27/2025 | New Video Generation options |
| 4/1/2026 | Added Sora 2 and Wan 2.5; updated all engine details |
Text2Video & Image2Video in the Generator?
We’re thrilled to announce a major new feature in the Civitai Generator – video generation! You can now create short video clips directly from text prompts, or by using a “starter” image. This exciting addition opens up fresh creative possibilities, making it easier than ever to bring your ideas to life in motion!
Over time, we’ll be adding more video generation tools to give you even more style options, control, and flexibility in your video creations. As we continue to expand, you’ll notice new tools, interface tweaks, and enhancements that make creating and customizing your videos more intuitive and powerful. Stay tuned for updates as we refine and grow this feature based on your feedback and our ongoing improvements and partnerships!
Note: For detailed information on navigating the Civitai Generator’s image creation interface, see our Guide to the Civitai Image Generator.
Tools
We currently have a number of choices for video generation, with more in the pipeline! Please note that the Buzz costs for each generation service are current at time of writing, but are subject to change.
Google’s Veo3
Veo?3 is Google DeepMind’s most advanced text-to-video generation model, released in May 2025, and marks a major leap beyond silent AI video. Now, it natively creates not only photorealistic visuals but also perfectly synchronized audio – everything from dialogue and ambient sound to music – all in one seamless output. The model excels at realistic physics, accurate lip-sync, and visual fidelity, enabling creators to bring cinematic scenes to life with just a prompt or an image input.
| Generation Options | Details | Changes Buzz Cost? |
|---|---|---|
| Text to Video | Accepts descriptive text prompts which are translated into video | |
| Image to Video | Accepts an image from which the video is derived | |
| Fast Mode | A faster, cheaper, less high-fidelity mode | Reduces base Buzz cost |
| Standard | The base, default model quality | |
| Prompt Enhancer | Adds cinematic flair, detail, and polish to prompts. | Increases base Buzz cost |
| Generate Audio | When enabled, will generate sound effects, speech, and/or music as specified. | Increases base Buzz cost |
Be aware that Veo 3 is a PG-only model due to Google’s strict policies. Any use of profanity or sexually explicit language in the prompt will result in a generic or unrelated PG video output, and you will not receive a refund.
You can view the Civitai Veo 3 generation gallery here.
Sora 2
Sora 2 is OpenAI’s latest video generation model, capable of producing highly detailed and coherent videos from text prompts or images. It supports both text-to-video and image-to-video workflows, with resolutions up to 1080p and durations of 4 or 8 seconds. A Pro mode option is available for higher quality outputs.
| Generation Options | Details | Changes Buzz Cost? |
|---|---|---|
| Text to Video | Accepts descriptive text prompts which are translated into video | |
| Image to Video | Accepts an image from which the video is derived | |
| Resolution | 720p / 1080p | 1080p increases base Buzz cost |
| Duration | 4 seconds / 8 seconds | 8 second option increases base Buzz cost |
| Aspect Ratio | 16:9 / 9:16 | Does not change base Buzz cost |
| Pro Mode | Higher quality output mode | Increases base Buzz cost |
Vidu Q1
Vidu delivers cutting-edge text-to-video generation, enabling users to create dynamic, visually compelling videos from simple prompts. Whether you’re aiming for cinematic flair, artistic stylization, or unique visual effects, Vidu offers a wide range of high-quality output styles to suit your creative needs. It also supports image-to-video and reference-to-video generation (using 3–7 reference images). Check out Vidu’s prompt guide for more information on how to get the best out of this phenomenal model!
| Generation Options | Details | Changes Buzz Cost? |
|---|---|---|
| Text to Video | Accepts descriptive text prompts which are translated into video | |
| Image to Video | Accepts an image from which the video is derived | |
| Reference to Video | Accepts multiple images (up to 7) from which aspects can be drawn to form the output video | |
| Prompt Enhancer | Adds cinematic flair, detail, and polish to prompts. | Does not change base Buzz cost |
| Style | General / Animation Style | Does not change base Buzz cost |
| Movement Amplitude | The desired amount of movement – Auto / Small / Medium / Large | Does not change base Buzz cost |
Hailuo by MiniMax
Hailuo, developed by the Chinese company MiniMax, is an innovative AI video generator that transforms text prompts and images into dynamic, high-quality videos. Launched in September 2024, it allows users to create videos using both text-to-video and img-to-video workflows, with a range of aspect ratios supported.
| Generation Options | Details | Changes Buzz Cost? |
|---|---|---|
| Text to Video | Accepts descriptive text prompts which are translated into video | |
| Image to Video | Accepts an image from which the video is derived | |
| Prompt Enhancer | Adds cinematic flair, detail, and polish to prompts. | Does not change base Buzz cost |
Kling
Kling AI, developed by Kuaishou Technology, is a cutting-edge text-to-video and image-to-video generation model that enables users to create high-quality videos from text descriptions or static images. Launched in June 2024, Kling can produce videos, accurately simulating real-world physics and complex motions. Its features include advanced camera controls, motion brushes for precise object movement, which aren’t available on Civitai.com’s Generator just yet, but we’re working on those!
| Generation Options | Details | Changes Buzz Cost? |
|---|---|---|
| Text to Video | Accepts descriptive text prompts which are translated into video | |
| Image to Video | Accepts an image from which the video is derived | |
| Version | v1.6 / v2 / v2.5 Turbo – Kling model versions | Newer models increase base Buzz cost |
| Prompt Enhancer | Adds cinematic flair, detail, and polish to prompts | Does not change base Buzz cost |
| Duration | 5 seconds / 10 seconds | 10 second option increases base Buzz cost |
| Mode | Standard quality / Professional Quality selector | Professional option increases base Buzz cost |
LTX Video 2
Lightricks LTX-Video was the first DiT-based video generation model capable of generating high-quality videos in real-time. It produces 24 FPS videos at a 768×512 resolution practically faster than they can be watched! It works in text-to-video and image-to-video modes, and it was the first video service running entirely in-house, on our own GPU hardware!
| Generation Options | Details | Changes Buzz Cost? |
|---|---|---|
| Text to Video | Accepts descriptive text prompts which are translated into video | |
| Image to Video | Accepts an image from which the video is derived | |
| Model | 19b-dev (full quality) / 19b-distilled (faster) | Model choice affects base Buzz cost |
| Resolution | 720p / 1080p | 1080p increases base Buzz cost |
| Aspect Ratio | 16:9 / 9:16 / 1:1 / 4:3 / 3:4 | Does not change base Buzz cost |
| Duration | 3 seconds / 5 seconds | 5 second option increases base Buzz cost |
| Generate Audio | When enabled, will generate sound effects and/or music | Increases base Buzz cost |
| Additional Resources | Accepts LoRAs | Each LoRA carries an additional Buzz cost |
Haiper
Haiper.ai’s 2.5 model, is a robust and advanced engine designed for producing both text-to-video and image-to-video content. This model brings a seamless, straightforward approach to video creation, requiring minimal setup to achieve impressive results.
Haiper.ai offer a range of helpful resources to ensure you get the most out of their video generation service. Since prompting for text-to-video can be a bit different than what we’re used to with text-to-image models on Civitai, these resources are designed to guide you through the nuances of video-focused prompts.


| Generation Options | Details | Changes Buzz Cost? |
|---|---|---|
| Text to Video | Accepts descriptive text prompts which are translated into video | |
| Image to Video | Accepts an image from which the video is derived | |
| Duration | 2 seconds / 4 seconds / 8 seconds video length | Modifies base Buzz cost |
| Resolution | 720p / 1080p / 4K (2160p) | Higher resolutions increase base Buzz cost |
| Prompt Enhancer | Adds cinematic flair, detail, and polish to prompts | Does not change base Buzz cost |
Mochi
Mochi 1 preview, by creators Genmo, is an open source, state-of-the-art, video generation model with high-fidelity motion and strong prompt adherence. Along with on-site Generation, Mochi can be used offline/locally, with ComfyUI and at least 12 GB of VRAM!
You can read our full Quickstart Guide to Mochi, here!
| Generation Options | Details | Changes Buzz Cost? |
|---|---|---|
| Text to Video | Accepts descriptive text prompts which are translated into video | |
| Prompt Enhancer | Adds cinematic flair, detail, and polish to prompts | Does not change base Buzz cost |
Note: Mochi currently supports text-to-video only.
Hunyuan
Hunyuan is Tencent’s powerful text-to-video generation model, now available on our platform with full video LoRA support. This allows for greater flexibility and fine-tuning of visual outputs to better match specific styles or themes. Hunyuan currently supports text-to-video generation with durations of 3 or 5 seconds.
| Generation Options | Details | Changes Buzz Cost? |
|---|---|---|
| Text to Video | Accepts descriptive text prompts which are translated into video | |
| Duration | 3 seconds / 5 seconds | 5 second option increases base Buzz cost |
| Additional Resources | Accepts LoRAs for fine-tuned outputs | Each LoRA carries an additional Buzz cost |
Note: Hunyuan currently supports text-to-video only.
Wan 2.1
Wan 2.1 is Alibaba’s foray into text-to-video technology, offering visually rich and coherent video outputs from natural language prompts. This model emphasizes strong scene consistency, smooth motion, and detailed artistic styles. It’s an excellent choice for creators looking to produce high-quality videos with minimal input. We’re continuing to monitor performance and explore expanded functionality – it’s not a lightweight model and requires significant hardware resources! Note: Wan 2.1 runs on our own hardware and can be used for adult content generation.
| Generation Options | Details | Changes Buzz Cost? |
|---|---|---|
| Text to Video | Accepts descriptive text prompts which are translated into video | |
| Image to Video | Accepts an image from which the video is derived | |
| Duration | 3 seconds / 5 seconds | 5 second option increases base Buzz cost |
| Additional Resources | Accepts LoRAs | Each LoRA carries an additional Buzz cost |
Wan 2.2
Wan 2.2 is the latest open-source, multimodal video generation model from Alibaba’s Wan AI platform. It introduces a Mixture-of?Experts (MoE) architecture, blending a high?noise and a low?noise models to significantly boost video quality.
This upgrade also brings huge gains in complex motion generation, having been trained on 65.6% more images and 83.2% more videos than its predecessor, Wan?2.1 – resulting in better generalization across semantics, dynamics, and aesthetics.
Note that Wan 2.2 is currently leveraging Fal.ai‘s generation API and is not hosted on our own in-house hardware. Generations must abide by Fal’s content policies. We are hoping to move Wan 2.2 generations onto our own Civitai hardware in the near future.
You can view the Civitai Wan 2.2 generation gallery here.
| Generation Options | Details | Changes Buzz Cost? |
|---|---|---|
| v2.2 | Latest, full, Wan version | |
| v2.2-5b | Latest, 5B parameter Wan version | |
| Text to Video | Accepts descriptive text prompts which are translated into video | |
| Image to Video | Accepts an image from which the video is derived | |
| Draft Mode (v2.2) | Applies an 8 step LoRA, faster generations, output quality somewhat reduced | Does not change base Buzz cost |
| Draft Mode (v.2.2-5b) | Switches to a Distilled Model, faster generations, output quality somewhat reduced | Does not change base Buzz cost |
| Resolution | 480p / 720p / 580p (v2.2-5b) | Higher resolutions increase baseBuzz cost |
| Duration | 3 seconds / 5 seconds | Does not change base Buzz cost |
| Shift | Influences the level of noise, and the level of motion/quality of output | Does not change base Buzz cost |
Wan 2.5
Wan 2.5 is the latest entry in Alibaba’s Wan video generation family, bringing significant improvements in quality and resolution. It supports text-to-video and image-to-video workflows with resolutions up to 1080p and durations of up to 10 seconds – making it one of the highest-resolution and longest-duration options available on the platform.
| Generation Options | Details | Changes Buzz Cost? |
|---|---|---|
| Text to Video | Accepts descriptive text prompts which are translated into video | |
| Image to Video | Accepts an image from which the video is derived | |
| Resolution | 480p / 720p / 1080p | Higher resolutions increase base Buzz cost |
| Duration | 5 seconds / 10 seconds | 10 second option increases base Buzz cost |
Image To Video
To try this, pick any image from your Generation Queue or Feed, then choose the “Image to Video” option from the context menu, or the Magic Wand menu, shown on any image.
The image will be loaded into the la Image to Video interface, where a prompt can be provided, specifying the desired movement.

There are multiple video tools with a capacity for image to video – when an image is loaded into the interface, you can select which you’d prefer to use from the dropdown list;

Bring Your Own Image – Img2Video From Any Image!
Bring Your Own Image (BYOI) lets you easily import images for our img2video services.
Drag images directly from Civitai, other websites, or your local PC into the drop-zone, or use an image URL. Supported formats include .png, .jpeg, .jpg, and .webp, with a maximum file size of 16 MB.
Images uploaded to the generator via BYOI are not posted to your Civitai Profile.
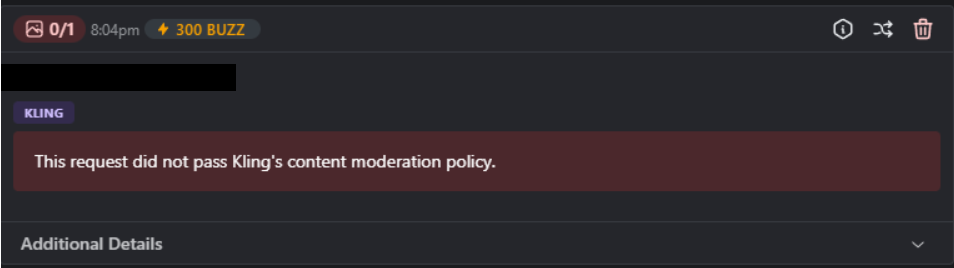
Be aware that uploaded images may be processed off-site by third-party video generation API providers and are subject to their policies and Terms of Service. Each service has its own content rules. If your request is denied by the partner API, you’ll receive a notification, and your Buzz will be refunded.
Note that when using BYOI, non-AI generated images, or AI images which we can’t read the metadata of, will only be valid for PG-rated outputs.
Limitations
- This is the first iteration of video generation to feature on Civitai.com, and as such it may lack some of the polish of other generation features! We’ll be improving video generation over time by tweaking the interface, introducing new quality and speed options, and implementing new Tools.
- Pricing! We know video gen is pricey; it’s cutting-edge, resource-demanding technology. We’re actively working with our inference partners to explore options that make it more accessible for everyone. Prices for all video generation options are subject to change!
- Terms of Service. While generating videos, you must adhere to Civitai’s standard Terms of Service. Additionally, please ensure you follow the Terms of Service specific to the tool you’re using for video generation.
- Results. Video generation can be unpredictable – getting the perfect output may take a few tries, as each result can vary, widely. Please note that we cannot refund generations that complete successfully but don’t meet your expectations.
Additionally, once a generation begins processing, it’s locked-in and cannot be canceled. You might be able to cancel immediately after starting, but once generation is underway, it’s committed. Of course, if the generation fails, refunds will be provided.
- Provider instability. Since many of the video options available via the Civitai Generator depend on external API partners to handle video generation requests, occasional failures, outages, or disruptions may occur that are outside of Civitai’s direct control.
- Kling Generation may return a “No Provider Supports this Job” error which is related to their API and not something we have control over. Jobs which return this error will be refunded instantly.
- Hailuo by Minimax does not have the concept of a seed. If running the same prompt, or the same input image with the same prompt, you’ll receive the same output. You will not be charged for this duplicate output.
- Hailuo by Minimax and Kling have relatively small concurrency limits; the number of jobs we can send to their API at the same time. At peak times, there may be a queue!
I need more help!
If you’re experiencing issues generating Video with the Civitai Image Generator and a solution isn’t mentioned on this page, please reach out to our Support Team at [email protected].
